Riapprovvigionamento prioritario dell'inventario in Excel con previsioni probabilistiche
L’incertezza è un aspetto inevitabile delle previsioni. Tuttavia, nel XX secolo, le previsioni statistiche sono emerse con la speranza che, dati modelli matematici adeguati, l’incertezza potesse essere eliminata. Di conseguenza, le prime teorie sulla supply chain hanno minimizzato o ignorato l’incertezza, poiché si pensava che le nuove o migliori tecniche di previsione avrebbero potuto eliminarla o, in caso contrario, renderla insignificante. Sebbene ben intenzionate, queste approcci erano difettose poiché l’incertezza, dopo un secolo di modellazione statistica, rimane irriducibile. Nel 2012, Lokad ha introdotto una prospettiva alternativa sulla supply chain, una prospettiva che abbraccia e quantifica l’incertezza. Questo approccio sfrutta le previsioni probabilistiche invece delle classiche previsioni puntuali time-series. In questa guida, e nel foglio di calcolo Microsoft Excel allegato, applichiamo previsioni probabilistiche al problema del riapprovvigionamento dell’inventario. Questo approccio porta a una politica di riapprovvigionamento dell’inventario prioritaria, qui dimostrata tramite Excel. Il nostro intento è duplice: primo, divulgare questo approccio a un pubblico che potrebbe non essere a suo agio con strumenti software più avanzati; e secondo, dimostrare che abbracciare l’incertezza richiede una certa mentalità più che strumenti sofisticati.
Download: probabilistic-inventory-replenishment.xlsx
1. Il problema del riapprovvigionamento dell’inventario
Il problema del riapprovvigionamento dell’inventario si concentra sull’individuazione della migliore lista di acquisto, una lista che tenga conto dei vincoli finanziari e degli obiettivi principali dell’azienda. Il metodo per produrre una tale lista dovrebbe funzionare allo stesso modo indipendentemente dai vincoli di budget, poiché il metodo cerca di massimizzare il rendimento dell’investimento per ogni dollaro speso. Il problema è che tutte le SKU sono in competizione per gli stessi dollari, quindi il rendimento finanziario di ogni unità di una SKU deve essere quantificato e classificato nel contesto di tutte le unità aggiuntive di ogni SKU.
1.1 La soluzione del riapprovvigionamento prioritario dell’inventario
Il processo di classificazione dell’inventario, come descritto sopra, richiede una prospettiva a livello micro. Per confrontare il rendimento derivante dall’aggiunta di qualsiasi unità di una SKU a una lista di acquisto, ci sono diversi fattori da considerare. In particolare, la probabilità di vendita fornita da una previsione di domanda probabilistica e i driver economici - ad esempio, il margine di profitto lordo e il prezzo di acquisto. Ogni quantità considerata, a sua volta, deve essere bilanciata rispetto ai vincoli interni ed esterni (come la capacità limitata del magazzino, i moltiplicatori di lotti e MOQs/MOVs, ecc.). I casi limite, come quando due (o più) unità hanno la stessa redditività attesa, devono essere considerati in una politica di riapprovvigionamento dell’inventario attraverso la valutazione dell’importanza relativa di ciascun prodotto. Le SKU non dovrebbero essere considerate in modo isolato, ma in cesti. Alcune SKU, nonostante abbiano margini di profitto più bassi se considerate singolarmente (come il latte), sono più importanti in quanto favoriscono le vendite di prodotti ad alto margine. Pertanto, il premio finanziario per il mantenimento dei livelli di servizio di un prodotto a margine inferiore - che facilita altre vendite - rappresenta un altro driver (“copertura degli stockout”)1. Un approccio di riapprovvigionamento prioritario dell’inventario (PIR), che utilizza la previsione probabilistica come input, tiene conto di tutti i fattori descritti sopra.
In breve, la soluzione PIR può essere riassunta in tre passaggi:
1. Creare una previsione di domanda probabilistica.
2. Elencare tutte le quantità di acquisto fattibili.
3. Classificare tutte le quantità di acquisto fattibili con i driver economici.
1.2 Riapprovvigionamento prioritario dell’inventario in Excel
Utilizzando dati finanziari per un negozio fittizio, inclusi i driver economici elencati nella sezione precedente, questo foglio di calcolo Excel modella la politica di riapprovvigionamento dell’inventario per tre SKU (penne, tastiere e librerie)2. Le conseguenze finanziarie di ogni unità aggiuntiva di SKU (se ordinata) e la probabilità di venderla sono illustrate nel foglio Charts (vedi Figura 1). I diagrammi e i grafici si aggiorneranno in base agli input e alle ipotesi del modello (ad esempio, livelli di stock iniziali, prezzi di acquisto e vendita, ecc.) nel foglio Control Tower (Figura 2). Viene generato un elenco dettagliato di opzioni decisionali fattibili nel foglio Micro purchasing decisions (Figura 3) in base agli input chiave. Questi input sono le previsioni di domanda probabilistiche dal foglio Distribution generators (Figura 4) e gli input dal foglio Control Tower. Infine, viene compilato un elenco di decisioni di riapprovvigionamento prioritario dell’inventario classificate in base al rendimento atteso dell’investimento (vedi foglio Ranked purchasing decisions nella Figura 5).
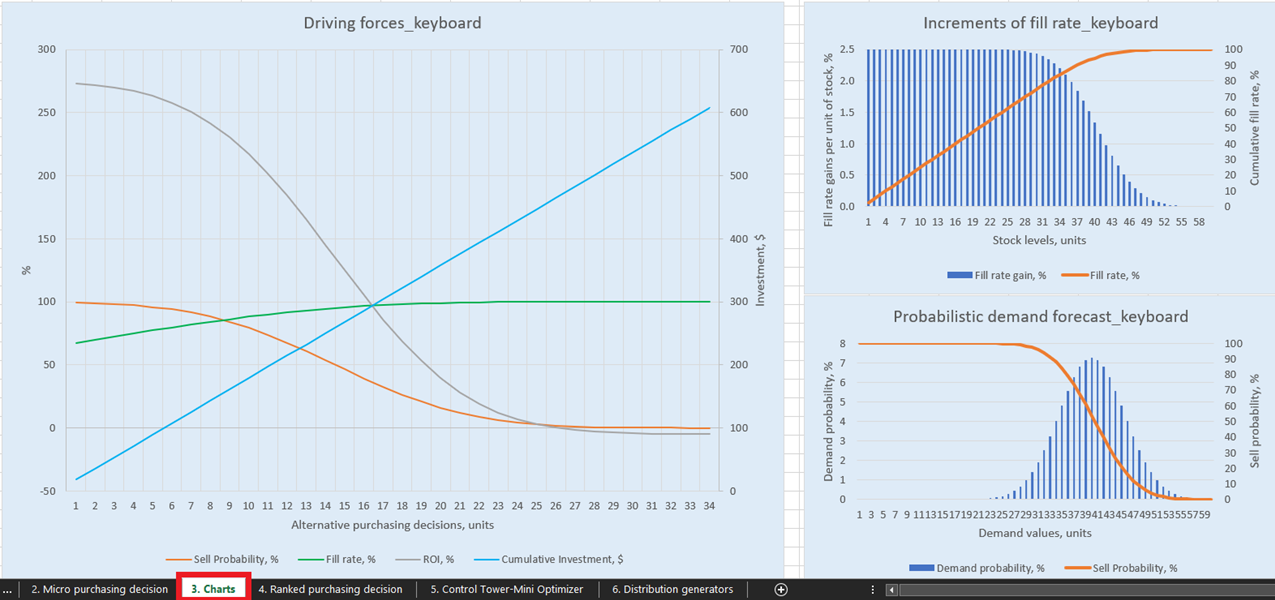
Figura 1. Vista di "Driving forces keyboard" in Charts, posizione evidenziata in rosso.
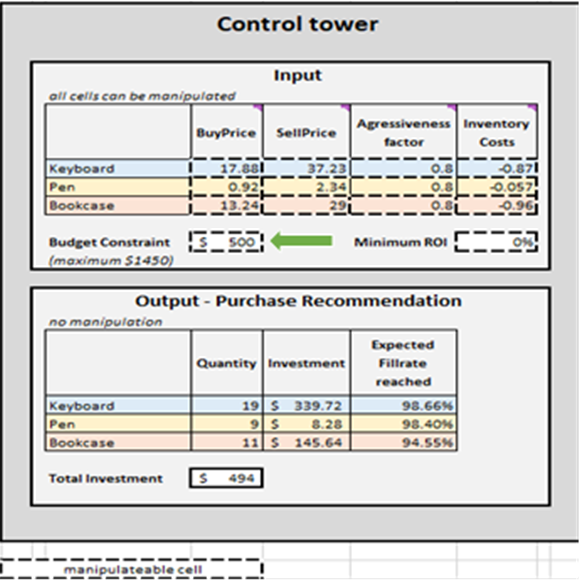
Figura 2. Vista di "Control Tower" situata in Control Tower - Mini Optimizer (foglio 5). È possibile modificare il "Budget Constraint" a qualsiasi valore compreso tra $0 e $1450 (vedi freccia verde).
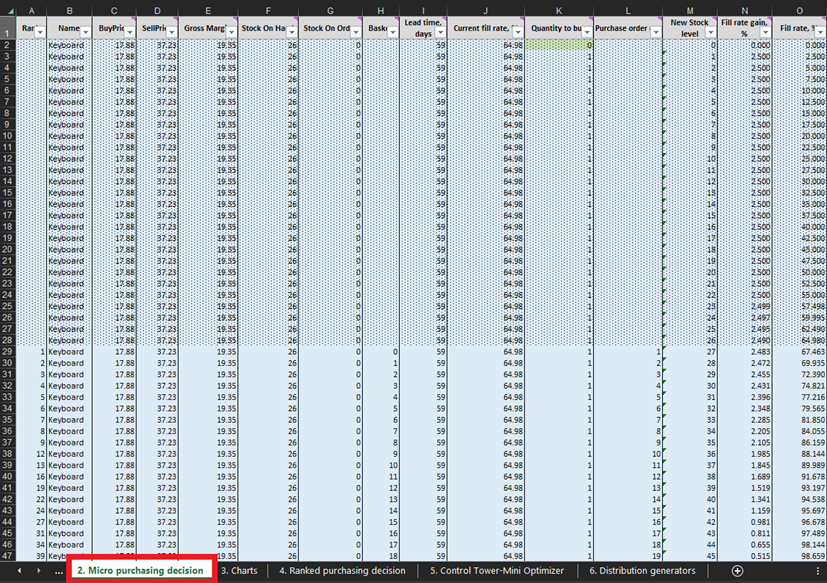
Figura 3. Dove posizionare le decisioni di acquisto micro all'interno di Excel, evidenziate in rosso. Le righe coperte dalla formattazione condizionale a tratteggio rappresentano dati passati (fino alla riga 28 inclusa nell'immagine precedente). Queste informazioni rappresentano decisioni di acquisto precedenti. Siamo interessati solo a tutto ciò che si trova al di sotto di questa formattazione condizionale. La stessa formattazione a tratteggio si applica ai dati della penna e della libreria.
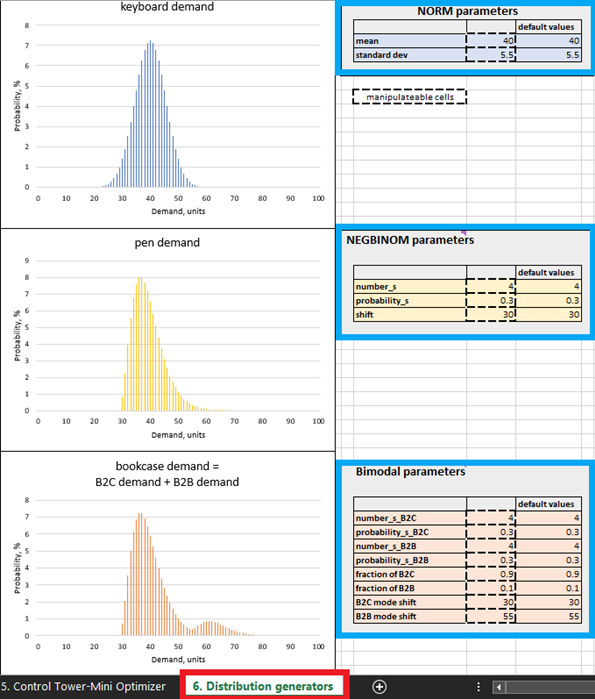
Figura 4. Dove posizionare i generatori di distribuzione all'interno di Excel, evidenziati in rosso. I pannelli di controllo del prodotto sono evidenziati in blu. Le celle con contorni tratteggiati possono essere manipolate.
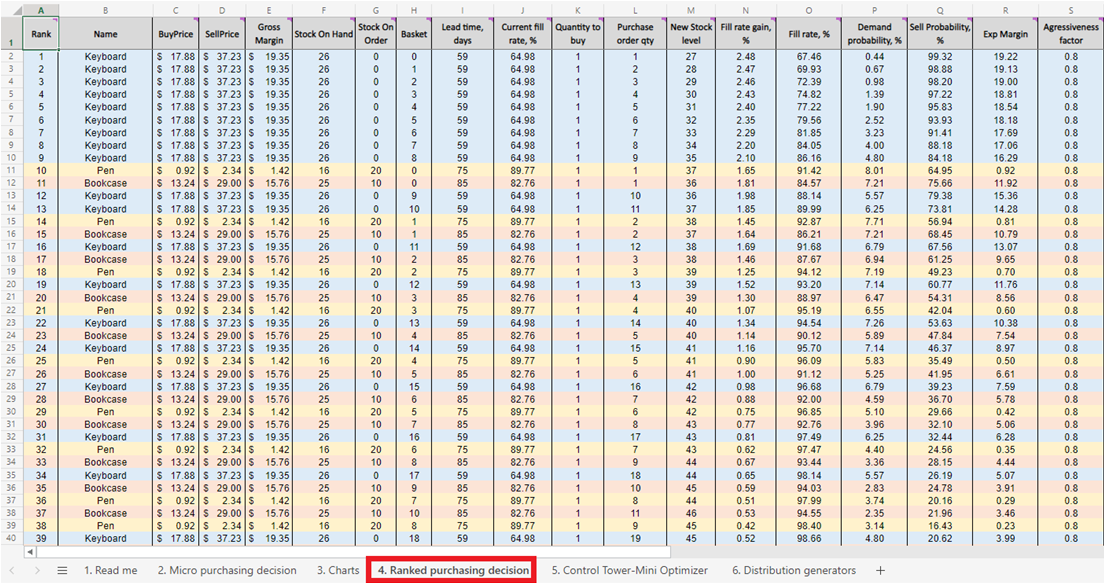
Figura 5. Un elenco di riapprovvigionamento di inventario prioritizzato delle decisioni di acquisto micro, situato nel foglio 4.
2. Previsione di domanda probabilistica
In questo contesto, una previsione probabilistica è un insieme di tutti i valori di domanda futura probabili e le rispettive probabilità. Essa abbraccia l’incertezza intrinseca della domanda futura e può essere costruita su qualsiasi periodo di tempo. Come una previsione tradizionale delle serie temporali, viene identificato un singolo valore di domanda più probabile (i punti bianchi nella Figura 6) e una linea di tendenza (la linea grigia che collega i punti bianchi). Tuttavia, una previsione probabilistica integra l’incertezza attraverso l’aggiunta di tutti i possibili valori di domanda (sebbene non equamente probabili). Questo approccio può essere visto nella Figura 6, dove diversi intervalli di confidenza rappresentano valori di domanda con diverse probabilità.
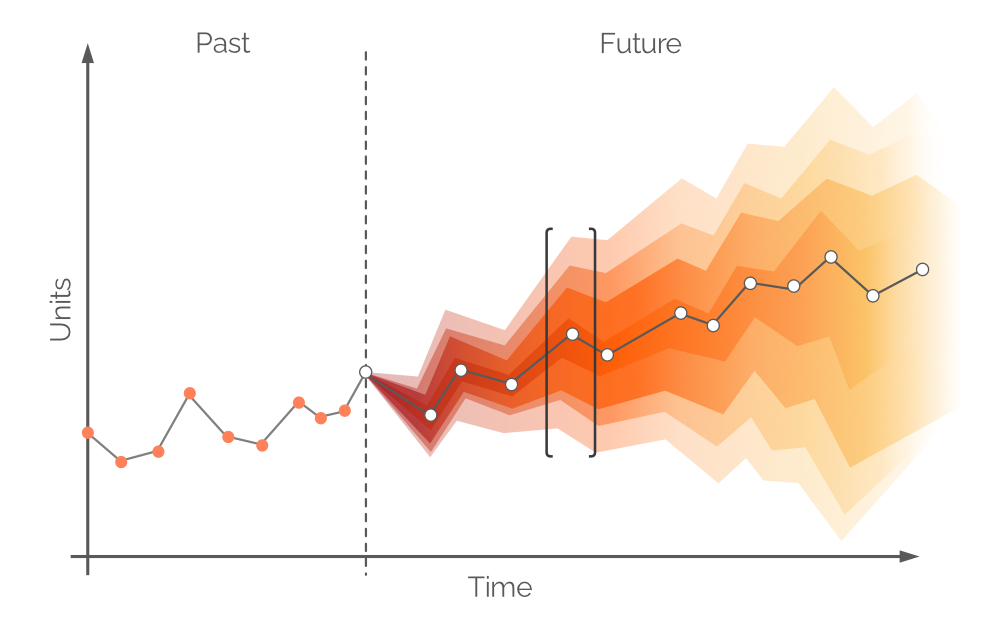
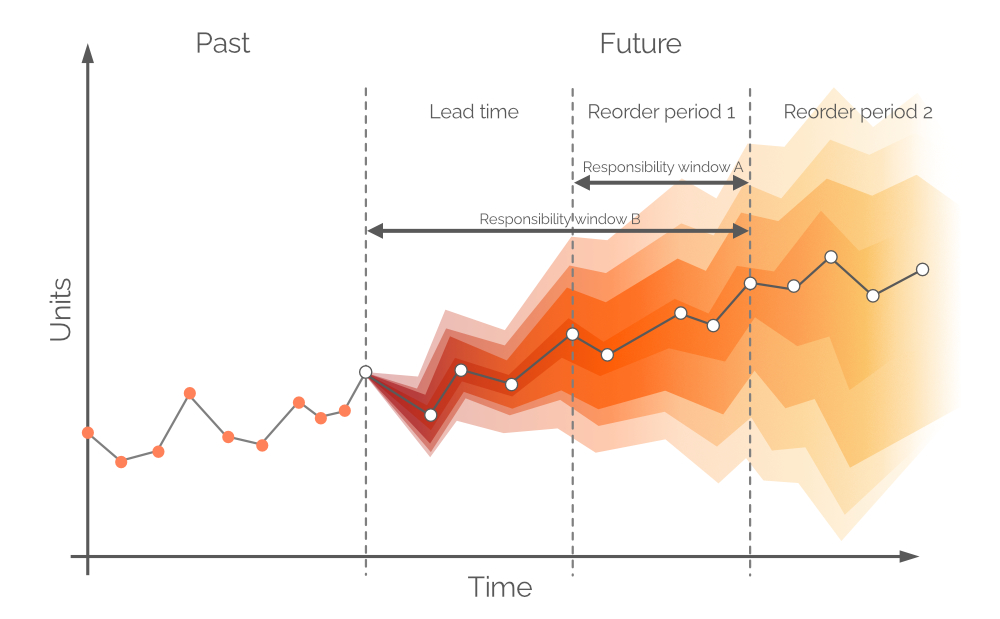
Figura 6. Una previsione probabilistica (domanda sull'asse y; tempo sull'asse x). La linea grigia verticale tratteggiata indica il momento attuale ("ora"). Il tempo è misurato in giorni, ma potrebbe essere qualsiasi intervallo desiderato. L'area tra parentesi quadre nere verrà discussa in seguito.
I punti bianchi nella Figura 6 rappresentano i valori di domanda più probabili a intervalli futuri fissi. C’è una banda di colore corrispondente a una gamma di valori di domanda futura alternativi - una distribuzione di probabilità a colori. Questo colore si attenua lungo l’asse verticale man mano che ci si allontana dal punto bianco, rappresentando una maggiore incertezza e una minore probabilità. Nel complesso, le bande di colore si attenuano man mano che il tempo passa (lungo l’asse orizzontale), poiché l’incertezza si intensifica con il passare del tempo. Tuttavia, indipendentemente dall’incertezza, c’è sempre almeno un valore che è il più probabile, e questo è rappresentato in ogni momento dai punti bianchi. Un esempio di una distribuzione di probabilità per un punto temporale è illustrato nella Figura 7.
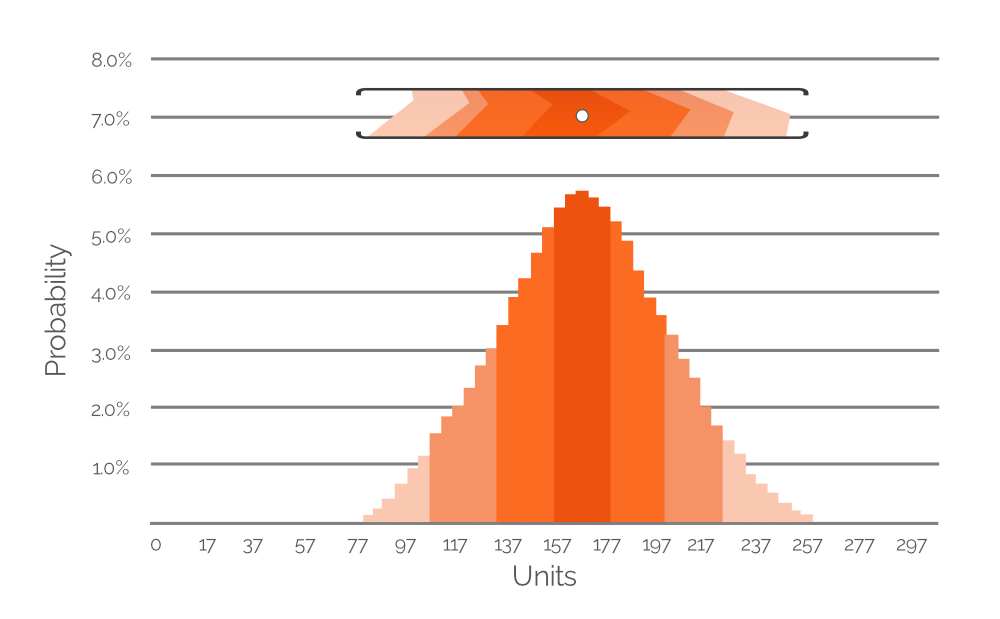
Figura 7. Un istogramma che rappresenta la probabilità di diversi valori di domanda possibili (a intervalli di 20 unità). L'asse Y è il valore di probabilità; l'asse X è la domanda in unità. L'istogramma è una rappresentazione dell'intervallo di valori evidenziato nella Figura 6 (incluso qui a scopo di riferimento).
La Figura 7 esprime i dati evidenziati dalla Figura 6 come un istogramma di probabilità, con valori numerici espliciti che indicano la probabilità di diversi valori di domanda. La codifica a colori è mantenuta per facilità di comprensione (ricordate, i colori più sbiaditi sono meno probabili; i colori più densi sono più probabili). In questo esempio, il valore di domanda più probabile è di 167 unità (+/-), motivo per cui il punto bianco nell’intervallo di valore ritagliato dalla Figura 6 è posizionato direttamente sopra la barra più alta nell’istogramma. Tuttavia, assegniamo anche probabilità di domanda a valori di domanda estremamente bassi e alti (circa 80 e 260 unità, rispettivamente, entrambi di colore arancione molto sbiadito). Questo dimostra la ricchezza potenziale dei dati di una previsione probabilistica e istogrammi simili sono inclusi nel foglio di calcolo di Excel - uno per ciascuno dei nostri SKU (vedi Figura 4). Utilizzando questi istogrammi (come nella Figura 7 sopra), è possibile identificare i valori di domanda (in unità) con probabilità non nulla di occorrenza e inserirli nel PIR.
2.1 La costruzione di una previsione probabilistica
Sebbene sia possibile creare una previsione probabilistica reale con dati storici in Excel, è argomentabile che sia lo strumento meno adatto a questo scopo. Nel complesso, i dettagli sulla creazione di una previsione probabilistica di produzione sono al di là dello scopo di questo documento, quindi sono state selezionate previsioni probabilistiche sintetiche per semplicità. I parametri di queste previsioni sintetiche possono essere manipolati nei generatori di distribuzione (vedi Figura 4). Tuttavia, si consiglia di studiare prima le impostazioni predefinite prima di apportare modifiche.
Nelle pratiche di supply chain mainstream, la domanda è tipicamente considerata distribuita normalmente, ma questa è una rarità. Nelle supply chain del mondo reale, la maggior parte degli SKU si discosta dai modelli di distribuzione normale. Date queste premesse, abbiamo deliberatamente selezionato tre diversi modelli di distribuzione: normale (per le tastiere), binomiale negativa (per le penne) e bimodale (per le librerie - una miscela di due modelli di distribuzione binomiale negativa). La seguente giustifica questa assunzione.
Ad esempio, assumiamo che le librerie siano acquistate sia da individui che da aziende (ad esempio, scuole), quindi utilizziamo una distribuzione bimodale. Nell’impostazione predefinita delle librerie, c’è una domanda frequente da parte degli individui, con uno o due pezzi acquistati per cliente. Questo rappresenta la prima modalità della distribuzione (vedi Figura 4). Le aziende, tuttavia, rappresentano fonti di domanda meno frequenti ma effettuano ordini più grandi (più grandi rispetto a quelli degli individui). Quando ciò accade, la loro domanda viene aggiunta alla domanda generata dagli acquisti degli individui e appare la seconda modalità della distribuzione. Questa seconda modalità è spostata verso destra (rappresentando valori di domanda elevati) ed è notevolmente più piccola della prima modalità, riflettendo il fatto che si verifica meno frequentemente (Figura 4). Il nostro modello assume anche che le penne siano acquistate da individui con una domanda occasionalmente elevata (ad esempio, studenti che acquistano prima delle date degli esami scolastici). Infine, per riflettere il fatto che una distribuzione normale si verifica occasionalmente, le vendite di tastiere seguono un modello di distribuzione normale.
All’interno dei Generatori di distribuzione (Figura 4), è possibile modificare le distribuzioni di domanda modificando i parametri nelle celle manipolabili. Ad esempio, aumentando la media per le tastiere (vedi “Parametri NORM” nella Figura 4) da 40 a 50, la distribuzione si sposterà di 10 unità verso destra. Come risultato di questo aumento della domanda media, il ROI previsto per tutte le unità di tastiera aumenterà. Allo stesso modo, è possibile apportare modifiche ai parametri delle distribuzioni binomiali negative (penne) e bimodali (librerie).
Poiché Excel manca di espressività per questo tipo di calcolo, questa dimostrazione limita le modifiche a 100 unità per prodotto. Ad esempio, impostando la media delle tastiere su 99, circa il 50% delle unità di domanda non riuscirà a calcolare nel foglio Micro purchasing decisions.
2.2 Selezione di un orizzonte per una previsione di domanda probabilistica
Tipicamente, le previsioni sono suddivise in intervalli giornalieri/settimanali/mensili, anche se questi periodi discreti hanno un’utilità e un valore limitati dal punto di vista del rifornimento. La domanda nei prossimi tempi di approvvigionamento non può essere coperta dalle decisioni di acquisto effettuate oggi a meno che non siano consentiti ordini arretrati, perché qualsiasi unità acquistata arriverà dopo un periodo pari al tempo di approvvigionamento. Pertanto, la domanda dovrebbe essere coperta con le scorte disponibili in negozio e le scorte in ordine (vedi Figura 8), assumendo che le unità in ordine arrivino prima della domanda. Pertanto, la previsione probabilistica si occupa della domanda tra i punti di riordino o, in altre parole, della domanda durante il Periodo di riordino 1 (vedi Figura 9). La domanda futura più distante sarà coperta con ordini futuri (vedi Periodo di riordino 2, in Figura 9).

Figura 8. Scorte disponibili (colonna F) e Scorte in ordine (colonna G), evidenziate in rosso, si trovano in Micro purchasing decisions. Il tempo di approvvigionamento, colonna I, è evidenziato in blu.
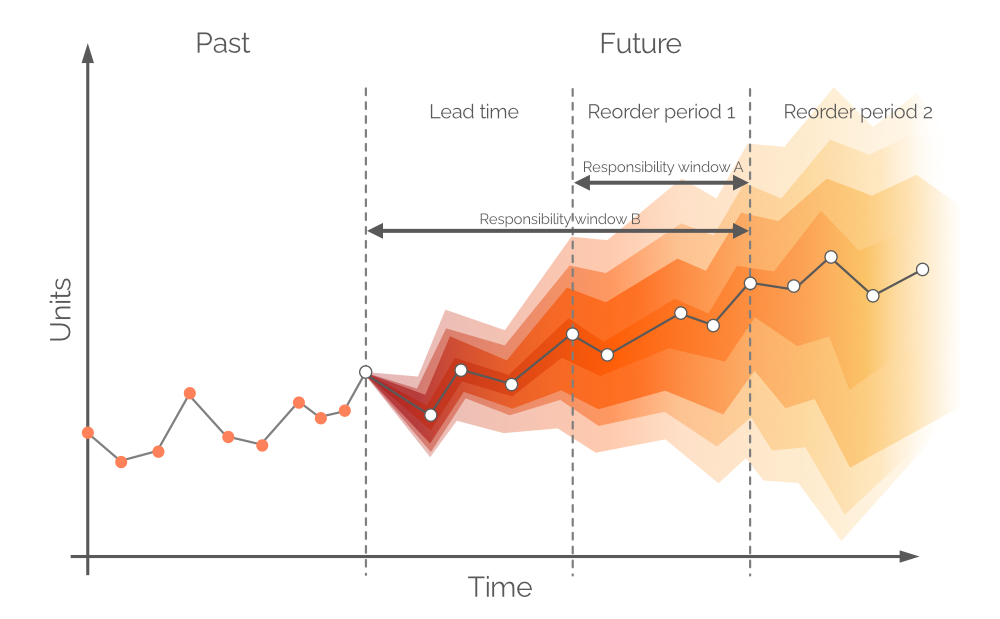
Figura 9. Una rappresentazione visiva delle finestre di responsabilità alternative. La domanda è sull'asse y, il tempo sull'asse x, con la linea grigia verticale tratteggiata a sinistra che indica il momento attuale ("ora", come nella Figura 6). La previsione probabilistica in questo documento si occupa della domanda nell'orizzonte uguale a Finestra di responsabilità B.
In teoria, la previsione di domanda probabilistica dovrebbe essere costruita nel periodo di tempo uguale a Periodo di riordino 1 - questa finestra di tempo è chiamata Finestra di responsabilità A (vedi Figura 9). Per fare ciò, dovremmo fare proiezioni future per le scorte disponibili e le scorte in ordine alla fine del tempo di approvvigionamento. Tuttavia, la domanda nel tempo di approvvigionamento - per la quale abbiamo già preso decisioni durante il periodo di ordine precedente - è anche probabilistica, e ciò comporterebbe livelli di scorte che sono distribuzioni di probabilità stesse3. Consentendo backorder (una pratica comune in alcuni settori), è possibile costruire una previsione probabilistica su un periodo congiunto (Tempo di approvvigionamento più Periodo di riordino 1, come nella Figura 9, anche chiamato Finestra di responsabilità B).
Si può presumere che i livelli attuali di scorte disponibili e scorte in ordine soddisfino la domanda durante il periodo di tempo di approvvigionamento. Se si verifica una rottura di stock, qualsiasi domanda successiva sarà coperta con backorder. Questi backorder saranno soddisfatti dalle micro decisioni di acquisto prese a partire da oggi. Ciò ci consente di trattare le scorte disponibili e le scorte in ordine come valori discreti (anziché casuali)4.
3. Identificazione delle opzioni di decisione di riapprovvigionamento fattibili
In uno scenario reale di riapprovvigionamento delle scorte, è necessario delineare tutte le opzioni di decisione fattibili, perché non esiste un modo diretto per passare da una previsione probabilistica alla singola migliore decisione (quantità di acquisto, in questo caso) per ogni prodotto. Invece di una singola scelta perfetta, un approccio probabilistico presenta una serie di decisioni possibili che devono essere prese in considerazione in termini di fattibilità.
Fattibilità qui ha il significato comune che una decisione è immediatamente attuabile; può essere eseguita “così com’è” senza ulteriori calcoli o controlli. Ad esempio, una decisione è “fattibile” se è redditizia e soddisfa tutti i nostri vincoli (ad esempio, MOQ, EOQ, dimensioni del lotto, spedizioni in container completi e qualsiasi altro vincolo che può esistere nella nostra supply chain)5.
Ad ogni riga del foglio Micro purchasing decisions (Figure 3 e 10), dobbiamo considerare l’aggiunta di un’unità di stock al nostro ordine di acquisto per un determinato prodotto6. Il nostro “presente” (o giorno 1 di questo esperimento) inizia alla riga 29, che mostra il livello attuale delle scorte. Questo viene calcolato come somma di Scorte Disponibili e Scorte in Ordine. Se decidiamo di aggiungere un’unità all’ordine di acquisto, la quantità complessiva dell’acquisto verrà calcolata nella colonna L come somma di tutte le unità considerate finora per l’acquisto (vedi note in Figura 10).
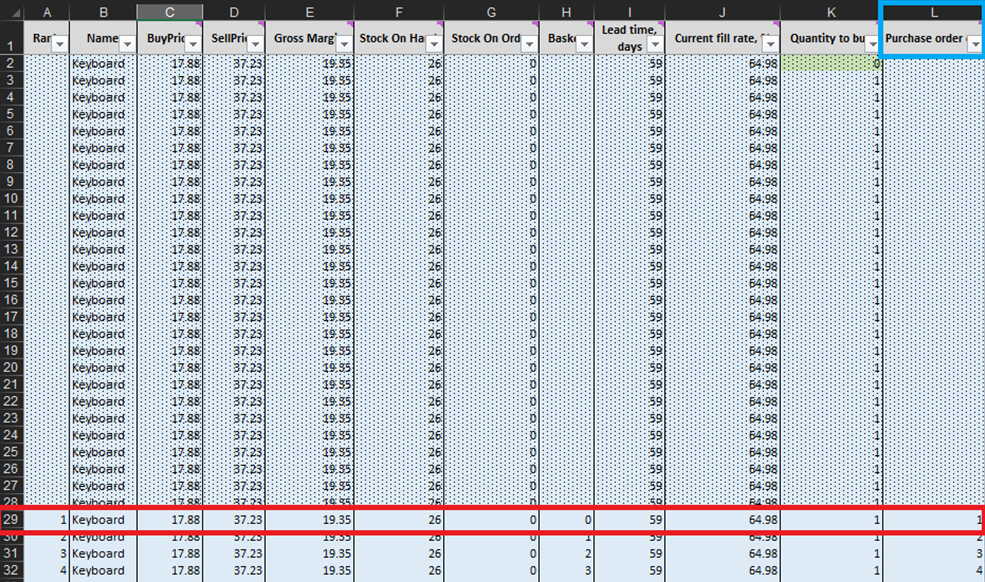
Figura 10. Vista dal foglio delle decisioni di acquisto micro. La riga 29, evidenziata in rosso, è dove inizia il nostro esperimento (per le tastiere). La colonna dell'ordine di acquisto è evidenziata in blu. Lo stesso principio si applica alle righe 140 (per gli ordini di penne) e 240 (per gli ordini di librerie).
Una volta identificate queste decisioni di inventario fattibili, calcoleremo e classificheremo la ricompensa economica di ogni possibile acquisto. Si noti che non valutiamo la ricompensa dell’acquisto per le unità che sono attualmente scorte disponibili o scorte in ordine (colonne F e G in Figura 10). Dato che abbiamo già acquistato queste unità, la ricompensa economica teorica è stata determinata (e classificata) in una data precedente. Ad esempio, se guardiamo i dati delle tastiere nella Figura 10, ci sono attualmente 26 unità in magazzino. Pertanto, inizieremo i calcoli alla riga 29 e considereremo se dovremmo ordinare la nostra prima unità di stock aggiuntivo (che aumenterebbe il livello delle scorte da 26 a 27 unità).
3.1 Valutazione delle Decisioni di Acquisto Fattibili
Per scegliere la migliore quantità di acquisto per ogni prodotto, è necessario calcolare il rendimento monetario atteso a livello di unità per ogni quantità fattibile per ogni prodotto (considerando il futuro incerto rappresentato dalla previsione probabilistica). Questo è un concetto di valore atteso adattato al livello più granulare dell’inventario decision-making.
In realtà, ogni tipo di driver economico dovrebbe essere preso in considerazione quando si cerca di calcolare il rendimento atteso per ogni decisione fattibile7. Ai fini di questa dimostrazione, ecco i fattori che considereremo:
- Prezzo di vendita: Quanto addebitiamo ai clienti per il prodotto.
- Costo di conservazione/stoccaggio: Quanto ci costa tenere il prodotto.
- Prezzo di acquisto: Quanto ci costa acquistare il prodotto dal nostro fornitore/grossista.
- Copertura delle scorte esaurite: Descritta in dettaglio di seguito in quanto è un driver meno conosciuto ma comunque importante8.
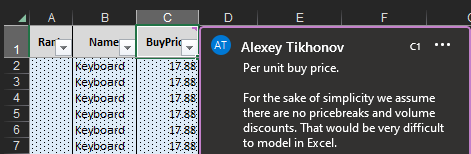
Figura 11. Nota esplicativa per il Prezzo di Acquisto, visibile passando il mouse sopra l'intestazione della colonna. C'è una definizione per ogni colonna in ogni foglio del documento Excel.
La copertura delle scorte esaurite rappresenta un incentivo finanziario per mantenere un’unità di un prodotto in magazzino, ma non con l’obiettivo esplicito di venderla. Questo driver economico viene utilizzato per modellare l’importanza relativa di un prodotto rispetto agli altri. Incentiva ad evitare una situazione di esaurimento delle scorte per i prodotti che potrebbero essere considerati meno importanti a causa del loro contributo marginale diretto, poiché questi prodotti potrebbero contribuire significativamente ai margini di profitto in modo indiretto. Pertanto, è più simile a un driver di ricompensa9. Anche se questo driver è sfumato, è fondamentale identificare tutti i prodotti critici (anche quelli che non sono driver di margine diretto).
3.2 Calcolo del Punteggio di Ogni Decisione Fattibile
La conseguenza economica totale (o ricompensa di acquisto) di una decisione di rifornimento di inventario è la somma di tutti i driver economici, inclusi margine previsto, costo di inventario previsto e copertura delle scorte esaurite (definiti in dettaglio di seguito). Il costo di stoccaggio è incluso in questi calcoli come un driver negativo, agendo come una forza contraria per bilanciare le nostre decisioni di rifornimento di inventario.
Di seguito è riportata un’analisi delle implicazioni economiche delle formule in ogni colonna, utilizzando la riga 29 del foglio Micro purchasing decisions come esempio (vedi Figura 12)

Figura 12. Suddivisione dei driver per colonne chiave, utilizzando la riga 29 di Micro purchasing decisions (foglio Excel 2). Alcune colonne sono state nascoste per comodità della figura.
Per calcolare la ricompensa prevista per ogni decisione, abbiamo bisogno dei seguenti driver:
Margine lordo (colonna E) = Prezzo di vendita - Prezzo di acquisto.
Probabilità di vendita (colonna Q) = controlla la formula nel foglio10.
Probabilità di non vendita (nessuna colonna) = 100% - Probabilità di vendita
Margine previsto (colonna R) = Margine lordo * Probabilità di vendita/100.
Fattore di aggressività (colonna S) = Varia da 0 a 1. 0,8 selezionato per questo strumento.
Copertura delle scorte esaurite (colonna T) = Prezzo di vendita * Fattore di aggressività * Probabilità di vendita
Costo di stoccaggio (colonna U)
Costo di inventario previsto (colonna V) = Costo di stoccaggio * probabilità di non vendita11.
Utilizzando i dati sopra riportati, la ricompensa di acquisto per ogni decisione di inventario a livello micro (ogni unità di ogni prodotto) viene calcolata nel seguente modo:
Ricompensa di acquisto (colonna W) = Margine previsto + Copertura delle scorte esaurite + Costo di inventario previsto.
Una volta ottenuta l’estimazione della ricompensa di acquisto, possiamo calcolare il punteggio finale che utilizzeremo successivamente per classificare tutte le decisioni prese in considerazione.
Punteggio (colonna Y) = Ricompensa di acquisto / Investimento (colonna X)12.
Poiché la copertura delle scorte esaurite è un driver sfumato che incorpora sia i rendimenti diretti che indiretti, la ricompensa di acquisto non è un riflesso rigoroso del rendimento previsto di una decisione di inventario isolata. Se si desidera calcolare questo tipo di rendimento, si escluderebbe la copertura delle scorte esaurite da questa formula13.
4. Classificazione delle Decisioni di Rifornimento di Inventari Fattibili
Una volta ottenuto il punteggio per ogni decisione di acquisto di inventario fattibile (per ogni prodotto), viene generata una lista e ordinata in ordine decrescente (dal più alto al più basso) in Ranked purchasing decisions (vedi Figura 13). Ogni decisione di inventario fattibile viene ordinata in base al ROI% positivo. Viene anche assegnata una classifica ordinale (1°, 2°, 3°, ecc.) a ciascuna decisione (vedi colonna A nella stessa figura).
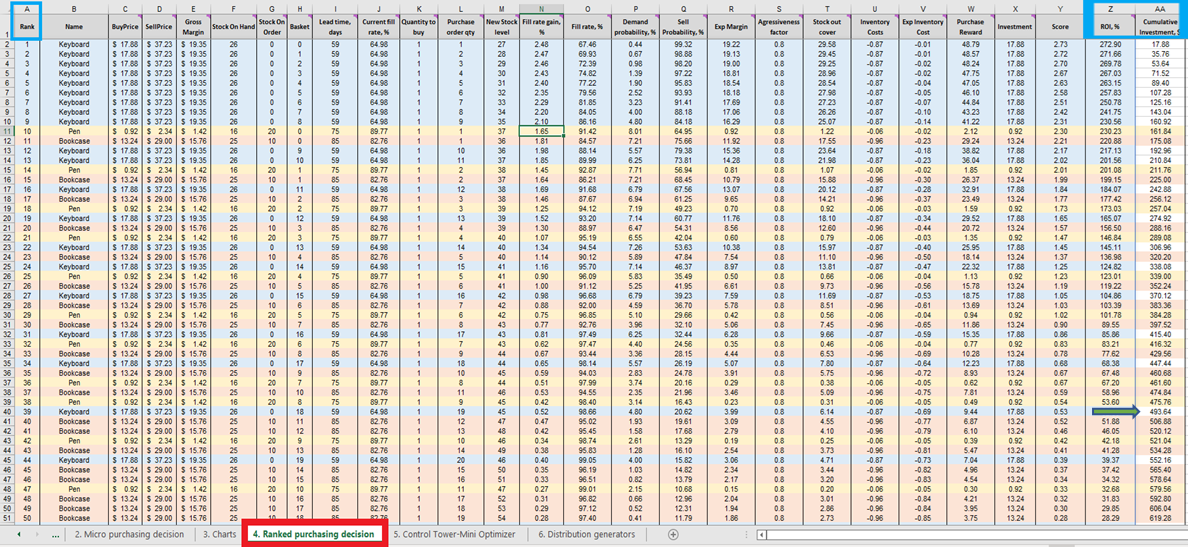
Figura 13. Posizione delle decisioni di acquisto classificate evidenziata in rosso. Le colonne A, Z e AA sono evidenziate in blu. La cella 40 (il punto di interruzione per un budget di $500 - il valore predefinito del foglio di calcolo) è indicata dalla freccia verde.
Le decisioni di acquisto classificate presentano righe colorate per ogni prodotto (tastiere, penne e librerie), utilizzate qui per dimostrare come la scelta di aggiungere un singolo unità aggiuntiva di qualsiasi prodotto interagisca con ogni altra unità aggiuntiva di ogni altro prodotto. Ciascuna di queste decisioni di inventario influenza collettivamente il ROI. Infine, viene calcolato un valore di investimento cumulativo (colonna AA, Figura 13). Questo può essere utilizzato per indicare dove si dovrebbero interrompere le decisioni di acquisto alla luce dei vincoli di budget, anche se questo è solo un possibile indicatore di interruzione14.
5. Determinazione dei Criteri di Interruzione
Per quanto riguarda la selezione di un punto di interruzione (sia nelle decisioni di acquisto classificate che nella realtà), i criteri varieranno a seconda di una serie di variabili. Ad esempio, si potrebbe avere un budget modesto e quindi massimizzare il ROI potrebbe essere problematico date le margine molto stretti. In alternativa, è possibile che si abbia un obiettivo complessivo per il livello di servizio e quindi si debba bilanciare questa priorità con la volontà di massimizzare i margini di profitto.
Per ottenere ancora più dettagli, i criteri di interruzione potrebbero includere la volontà di massimizzare il ROI con obiettivi di livello di servizio variabili per ogni prodotto o categoria. I criteri di interruzione sono quindi una scelta strategica che dovrebbe essere fatta dopo una riflessione sincera sugli obiettivi aziendali complessivi. Il ripristino prioritario dell’inventario (PIR) è notevolmente flessibile in questo senso; i criteri di interruzione per ogni ciclo di acquisto possono essere regolati utilizzando la stessa procedura di classificazione complessiva.
Per visualizzazioni esplicite delle nostre possibili decisioni di rifornimento di inventario, ci sono tre grafici per ogni prodotto nel dashboard Charts (foglio 3, vedi Figura 14). Di particolare interesse è “Driving forces_product name” (nell’esempio di Keyboard utilizzato nella Figura 14), che mostra l’evoluzione del ROI dati diverse quantità di acquisto a livello di unità.
Come si può vedere dal grafico, c’è un punto in cui l’aumento delle quantità di acquisto comporterà un ROI negativo. Questo perché, a un certo livello, non ha senso acquistare più unità poiché i margini previsti saranno ridotti in modo critico dai costi di inventario previsti aumentati.
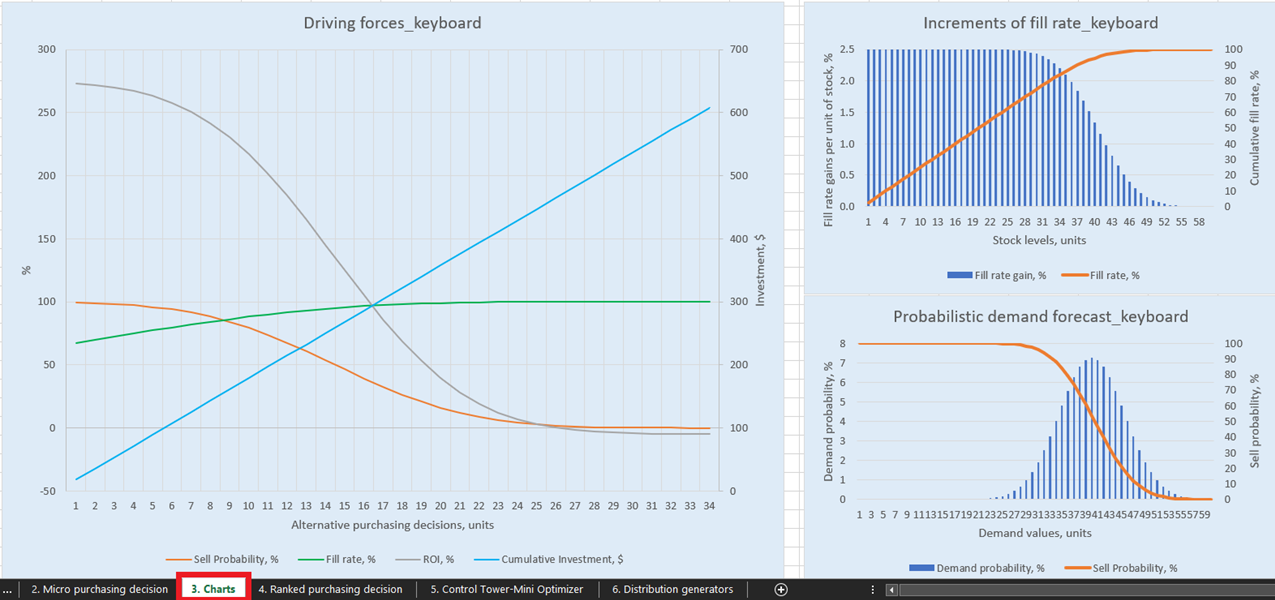
Figura 14. Vista di "Driving forces_keyboard" in Charts, posizione evidenziata in rosso.
Una volta determinati i criteri di terminazione, le decisioni di rifornimento di inventario prioritarie vengono aggregate per SKU, che a loro volta aggiornano Quantità, Investimento e Tasso di riempimento previsto raggiunto in Output-Raccomandazione di acquisto per ogni SKU (vedi Figura 15). È possibile modificare i vincoli di budget ($0 a $1450), che a loro volta aggiorneranno l’elenco di acquisto consigliato. Per comodità, la torre di controllo presenta due blocchi aggiuntivi: Caso base - copia cartacea e Modifiche allo scenario di base. Il primo è statico e mostra le impostazioni predefinite per la dimostrazione come progettate da Lokad; il secondo mostra la differenza tra le eventuali modifiche apportate e le impostazioni predefinite di Lokad.
L’elenco di raccomandazione di acquisto nella Torre di controllo rappresenta l’obiettivo di questa dimostrazione (vedi Figura 15).
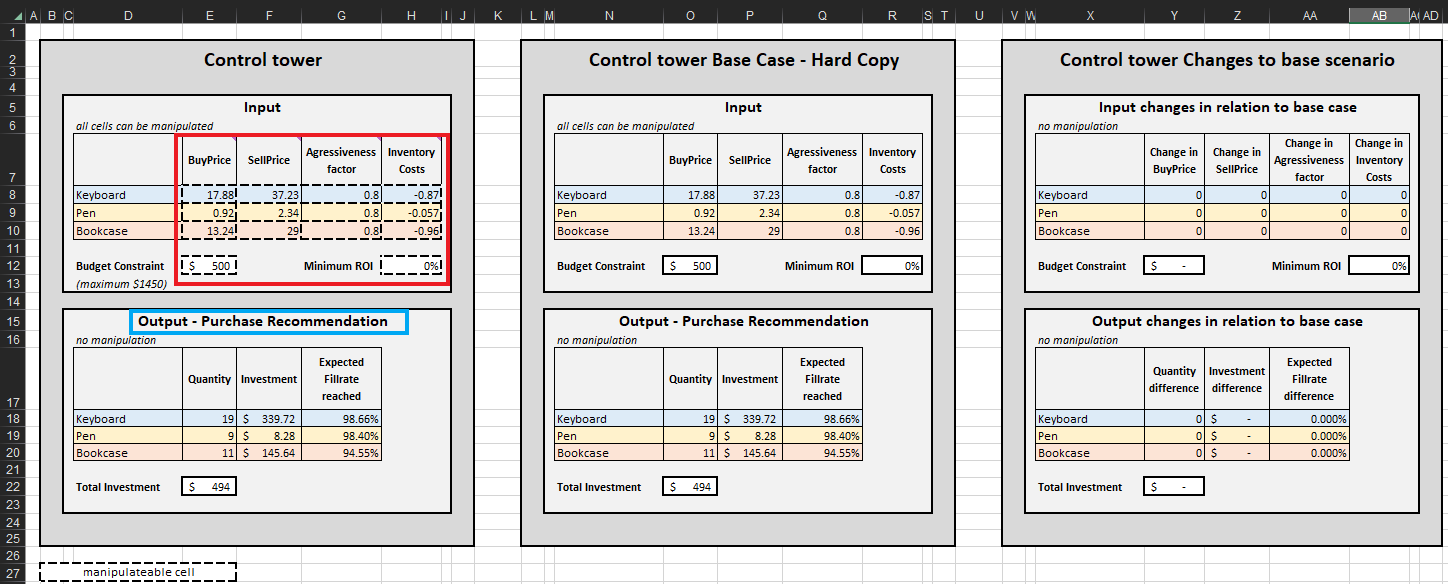
Figura 15. Vista di Control Tower-Mini Optimizer (foglio 5). Le celle manipolabili sono evidenziate in rosso. "Raccomandazione di acquisto" è evidenziato in blu e rappresenta l'obiettivo di un approccio prioritario al rifornimento di inventario.
6. Conclusioni
Le previsioni tradizionali delle serie temporali sono semplicemente incapaci di catturare il livello di dettaglio necessario per prendere decisioni di rifornimento di inventario che riflettano l’incertezza futura e l’intera portata dei vincoli e dei driver. Questo perché mancano di una dimensione di incertezza esplicita, rappresentata da valori di probabilità per i risultati futuri attesi. Poiché una serie temporale tradizionale è effettivamente cieca a questo tipo di dati, un metodo classico di gestione come la scorta di sicurezza si riduce a un tentativo; se non sufficiente, si perdono vendite redditizie con un ROI previsto positivo; se troppo, si riduce l’ROI accumulando unità che (come dimostrato nel foglio di calcolo) hanno un ROI previsto negativo.
Il rifornimento di inventario prioritario, utilizzando previsioni probabilistiche, è la nostra soluzione a questo problema. Un tale approccio considera le scelte di rifornimento di inventario in combinazione, anziché in isolamento. In questo modo, la ricompensa finanziaria prevista delle nostre scelte di rifornimento di inventario può essere completamente quantificata e rivelata. La base di un tale approccio è l’accettazione dell’incertezza e l’utilizzo di input di previsione probabilistica. A sua volta, è possibile ottenere una maggiore comprensione di quali livelli di servizio (per SKU) producono ricompense finanziarie significative, anziché stabilire obiettivi arbitrari.
L’approccio PIR dimostrato in questo documento è stato costruito utilizzando dati sintetici e parametri ristretti. Queste scelte sono state fatte per adattare uno strumento comune (Excel) a uno scopo insolito (PIR). Tra le altre concessioni necessarie, gli SKU e le unità sono state limitate (rispettivamente a 3 e 100) per ridurre i tempi di elaborazione, poiché l’elaborazione di un catalogo completo (per non parlare dei dati di più negozi) sarebbe troppo laboriosa. Inoltre, non sono state aggiunte restrizioni alle catene di approvvigionamento. Crucialmente, Excel non è progettato per elaborare variabili casuali - un passaggio fondamentale per generare previsioni probabilistiche e politiche PIR. Queste limitazioni non si applicano a una soluzione PIR di produzione.
Gli operatori di supply chain le cui attività hanno superato Excel sono invitati a inviare un’e-mail a contact@lokad.com per organizzare una dimostrazione di una soluzione PIR di produzione.
7. Panoramica del foglio di calcolo
7.1 Leggimi
Questo foglio serve come pagina iniziale per l’utente. C’è un link a un tutorial online (quello che stai leggendo ora).
7.2 Decisioni di acquisto micro
Questo è il secondo foglio ed è dedicato all’analisi finanziaria fine-granulare di tutte le opzioni di decisione di riapprovvigionamento fattibili. Si prega di notare che qui non viene eseguita alcuna manipolazione manuale dei dati. Questo foglio mostra solo i risultati dei calcoli basati sugli input dei fogli Control Tower e Distribution generators.
Caratteristiche principali:
- Le righe con formattazione condizionale sono “decisioni passate” e non possono essere modificate. Consigliamo di utilizzare un’app desktop poiché quella basata sul browser di Excel talvolta non è affidabile in termini di formattazione.
- Passando il mouse su ciascun titolo di colonna verrà visualizzata una definizione/nota utile.
7.3 Grafici
Questo è il terzo foglio ed è dedicato alla visualizzazione dei principali fattori in gioco nelle decisioni di riapprovvigionamento dell’inventario. Si prega di notare che qui non viene eseguita alcuna manipolazione manuale dei dati. Questo foglio è progettato per aiutare l’operatore a visualizzare (e quindi comprendere meglio) il funzionamento interno del processo PIR.
Caratteristiche principali:
- Tre grafici per SKU (tastiera, penna e libreria).
- Il grafico delle “forze trainanti” visualizza le principali forze trainanti per ogni decisione a livello di unità (per ogni SKU). Questo è il motivo per cui l’asse x contiene solo le unità di un SKU che devono ancora essere ordinate.
- Altri due grafici (“incrementi del tasso di riempimento” e “previsione di domanda probabilistica”) contengono tutte le unità di stock - stock disponibile e le unità che possono essere ordinate.
7.4 Decisioni di acquisto classificate
Questo è il quarto foglio ed è dedicato all’elenco di tutte le decisioni di riapprovvigionamento fattibili, ordinate per ROI/punteggio in ordine decrescente. Questo elenco viene ordinato automaticamente dai dati del foglio 2 (Decisioni di acquisto micro). Le decisioni fattibili vengono visualizzate in relazione l’una all’altra (vedi “Caratteristiche principali” di seguito). Si prega di notare che qui non viene eseguita alcuna manipolazione manuale dei dati. A seconda delle modifiche apportate agli input nei fogli 5 e 6, questa lista cambierà.
Caratteristiche principali:
- Le decisioni di riapprovvigionamento dell’inventario fattibili vengono classificate in ordine decrescente (dal più alto al più basso) per ROI/punteggio.
- Viene calcolato l’investimento cumulativo per le decisioni ordinate (vedi colonna AA nel foglio 4).
- Passando il mouse su ciascun titolo di colonna verrà visualizzata una definizione/nota utile.
7.5 Control tower-mini optimizer
Questo è il quinto foglio e riassume le ipotesi del modello (input) e le decisioni consigliate (output). I dati nelle celle manipolabili possono essere modificati per alterare le ipotesi del modello e quindi l’output del modello.
Caratteristiche principali:
- Tre blocchi per assistere nella dimostrazione: “Control tower” per la manipolazione manuale degli input; “Caso base - Copia fisica” per visualizzare le impostazioni predefinite; e “Modifiche allo scenario di base” per visualizzare la differenza tra le impostazioni aggiornate e predefinite (vedi foglio 5).
- Un quarto blocco (“Ipotesi del modello”), situato sotto “Control tower”, è dedicato alla manipolazione delle ipotesi di stock iniziali (vedi foglio 5).
- Solo i dati nelle celle manipolabili possono essere modificati.
7.6 Generatori di distribuzione
Questo è il sesto foglio ed è dedicato alla generazione di previsioni di domanda probabilistiche. I parametri nelle celle manipolabili possono essere modificati, il che comporterà l’aggiornamento delle distribuzioni e la visualizzazione di nuovi valori di probabilità di domanda.
Caratteristiche principali:
- Un grafico di distribuzione per SKU.
- Ogni SKU ha un diverso pattern di distribuzione (ragionamento spiegato nella sezione 2.1).
- C’è una tabella a sinistra dei grafici di distribuzione, dedicata alla manipolazione dei parametri delle distribuzioni.
- Solo i parametri nelle celle manipolabili possono essere modificati.
- Passando il mouse sui titoli di colonna pertinenti (nella tabella) verrà visualizzata una definizione/nota utile.
Note
-
Considera latte e cioccolato. Il primo è un prodotto a basso margine, ma è considerato un prodotto di base, mentre il secondo è discrezionale con margini di profitto più alti. Le persone tendono a comprare prodotti di base e prodotti discrezionali insieme, ma la penalità per non avere latte è diversa da quella per il cioccolato. Un cliente potrebbe sostituire un prodotto discrezionale (biscotti) con un altro (cioccolato) in caso di esaurimento delle scorte, ma se non può comprare un prodotto di base (latte), potrebbe lasciare completamente il negozio. Questo è il motivo per cui la copertura delle scorte sarebbe maggiore per il latte rispetto al cioccolato, indipendentemente dal margine di profitto lordo. Dal nostro punto di vista, la copertura delle scorte è una ricompensa piuttosto che una penalità, in quanto è destinata a consentire una maggiore vendita. ↩︎
-
Tre prodotti sono sufficienti per illustrare il concetto, ma anche per mantenere il documento conciso e comprensibile. ↩︎
-
I livelli di stock diventano probabilistici quando sottraiamo la domanda probabilistica dai valori discreti dello stock (valore discreto meno distribuzione di probabilità produce un’altra distribuzione di probabilità). Tutto ciò renderebbe troppo complicato spiegare le cose tramite Excel, in quanto non è adatto a eseguire calcoli con variabili casuali (pensa alle ‘distribuzioni di probabilità della domanda’). ↩︎
-
Queste concessioni sono necessarie per dimostrare il principio generale di un approccio probabilistico. In realtà, gli ordini in arretrato non vengono sempre utilizzati e i tempi di consegna sono probabilistici e soggetti a modifiche. ↩︎
-
Per semplicità, non abbiamo applicato vincoli di supply chain. ↩︎
-
Come già accennato, non è necessario modificare alcun dato nelle decisioni di acquisto Micro. Tutta la manipolazione dei dati viene effettuata tramite i fogli 5 e 6. ↩︎
-
In questo foglio Excel, i driver economici sono espressi in dollari, anche se la valuta è irrilevante. ↩︎
-
L’elenco dei driver economici sopra non è esaustivo e gli scenari reali di riapprovvigionamento dell’inventario (e della supply chain) quasi certamente ne includeranno di più. Questo è particolarmente vero quando si tratta della produzione di beni e dei vincoli di deperibilità. ↩︎
-
Questo driver è più sfumato in un contesto B2C rispetto a uno B2B. Per quest’ultimo, spesso sono presenti penalità esplicite associate agli eventi di esaurimento scorte, come le penalità contrattuali; per il primo, è difficile quantificare finanziariamente l’impatto negativo di un evento di esaurimento scorte. In generale, sarà elevato per i prodotti che infliggono un pedaggio negativo sproporzionato sull’attrattività di un’azienda (indipendentemente dal contributo marginale diretto dello SKU). Il latte, come già detto, non è un driver di margine per i supermercati, ma la sua posizione strategica (di solito alla fine del supermercato) spinge i clienti a percorrere corsia dopo corsia di altri prodotti (quasi tutti con margini più alti). Se un supermercato si trova ad affrontare un evento di esaurimento scorte con questo prodotto di base (uno che le persone tendono a comprare molto spesso e in ceste), questo potrebbe spingere i clienti ad abbandonare il supermercato, fare acquisti altrove e eventualmente non tornare (se questi eventi di esaurimento scorte sono frequenti). ↩︎
-
La probabilità di vendita deriva dalle distribuzioni di probabilità generate nei generatori di distribuzione (foglio 6). ↩︎
-
Il costo continuativo per non riuscire a vendere e quindi dover conservare un’unità invenduta di uno SKU. ↩︎
-
L’investimento è, in questo scenario, lo stesso del prezzo di acquisto, ma solo perché le nostre decisioni di acquisto non sono vincolate da MOQ o multipli di lotto. ↩︎
-
Il modo più semplice per farlo è impostare il fattore di aggressività (colonna S nella Figura 12) a zero, cosa che un’azienda potrebbe fare se decidesse che un evento di esaurimento scorte non ha impatti negativi. Un consiglio gratuito: sicuramente li ha. ↩︎
-
Ad esempio, il nostro budget predefinito è di $500, quindi termineremmo le nostre decisioni di acquisto alla cella 40 (vedi Figura 13), poiché la cella 41 ha un valore di $506.88 ed è al di là del nostro budget. Aggregheremmo quindi i numeri per prodotto, che costituirebbero il nostro elenco di acquisti (vedi Output - Raccomandazione di acquisto in Control Tower, come nella Figura 2). Come già detto, è possibile modificare il budget preimpostato di $500 (vedi Figura 2 per le istruzioni) a un valore compreso tra $0 e $1450. Ciò dimostrerà come l’elenco di acquisti cambia con diversi vincoli di budget. Indipendentemente dalle limitazioni finanziarie, le Decisioni di acquisto classificate identificheranno la migliore combinazione possibile di decisioni di inventario, dal punto di vista del ROI, per tutte le righe comprese tra il rango 1 e il punto di terminazione. ↩︎