Valore Aggiunto Previsionale
Il valore aggiunto previsionale1 (FVA) è uno strumento semplice per valutare le prestazioni di ciascun passaggio (e contributore) nel processo di previsione della domanda. Il suo obiettivo finale è eliminare gli sprechi nel processo di previsione rimuovendo i punti di contatto umani (sostituzioni) che non aumentano l’accuratezza delle previsioni. Il FVA si basa sull’idea che una maggiore accuratezza delle previsioni vale la pena perseguire e che identificare le sostituzioni che la aumentano, ed eliminare quelle che non lo fanno, è auspicabile. Nonostante le intenzioni positive, il FVA dimostra una limitata utilità una tantum e, se utilizzato su base continuativa, presenta una moltitudine di svantaggi tra cui assunzioni matematiche difettose, idee sbagliate sul valore intrinseco dell’aumento dell’accuratezza delle previsioni e l’assenza di una solida prospettiva finanziaria.

Panoramica del Valore Aggiunto Previsionale
Il valore aggiunto previsionale mira ad eliminare gli sprechi e aumentare l’accuratezza della previsione della domanda incoraggiando - ed valutando - i contributi di più dipartimenti (inclusi team non di pianificazione della domanda, come Vendite, Marketing, Finanza, Operazioni, ecc.). Valutando il valore di ciascun punto di contatto umano nel processo di previsione, il FVA fornisce alle aziende dati utili sulle sostituzioni che peggiorano la previsione, offrendo loro l’opportunità di identificare ed eliminare sforzi e risorse che non contribuiscono a una migliore accuratezza delle previsioni.
Michael Gilliland, il cui The Business Forecasting Deal ha attirato l’attenzione del grande pubblico sulla pratica, argomenta2
“Il FVA aiuta a garantire che tutte le risorse investite nel processo di previsione - dall’hardware e software informatico al tempo e all’energia degli analisti e della direzione - stiano migliorando la previsione. Se queste risorse non stanno aiutando a prevedere, possono essere tranquillamente reindirizzate verso attività più meritevoli”.
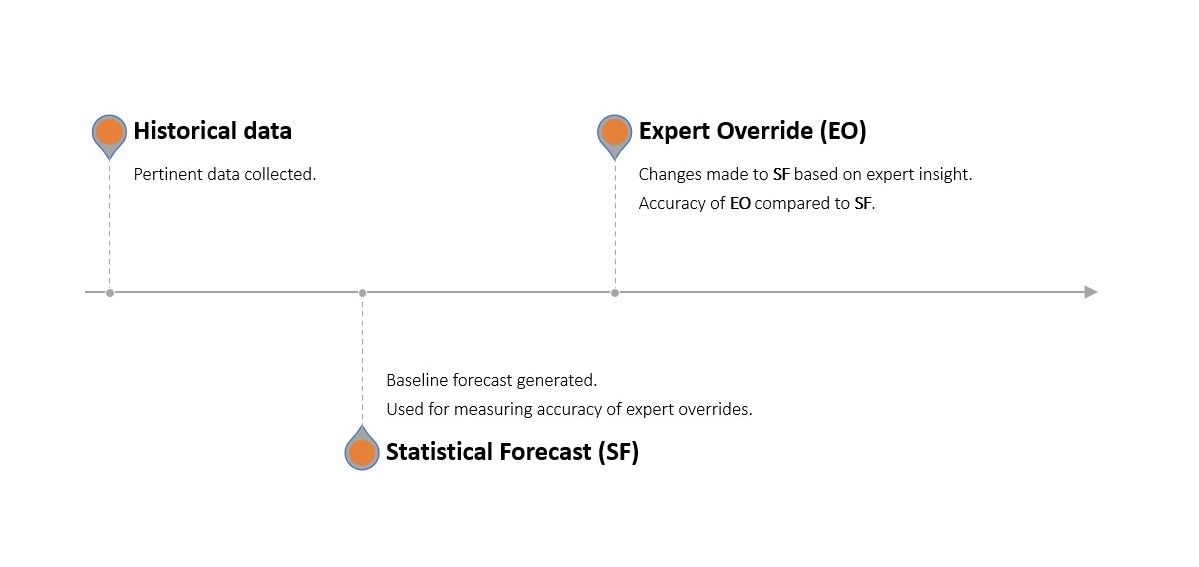
Si identificano quali attività e risorse stanno aiutando attraverso un processo di previsione a più fasi in cui viene generata una previsione statistica utilizzando il software di previsione esistente dell’azienda. Questa previsione statistica viene quindi sottoposta a modifiche manuali (sostituzioni) da parte di ciascun dipartimento selezionato. Questa previsione adattata viene quindi confrontata con una previsione ingenua di riferimento (senza modifiche, agendo come un placebo) e con la domanda reale osservata.
Se le modifiche apportate dai dipartimenti hanno reso la previsione statistica più accurata (rispetto alla previsione statistica intatta), hanno contribuito un valore positivo. Se l’hanno resa meno accurata, hanno contribuito un valore negativo. Allo stesso modo, se la previsione statistica era più accurata del placebo, ha aggiunto un valore positivo (e viceversa se era meno accurata).
Il FVA è, quindi, “[una misura] del cambiamento in una metrica delle prestazioni di previsione che può essere attribuito a un particolare passaggio o partecipante nel processo di previsione”2.
I sostenitori del valore aggiunto previsionale sostengono che sia uno strumento essenziale nella moderna gestione della supply chain. Identificando quali parti del processo di previsione sono utili e quali no, le organizzazioni possono ottimizzare l’accuratezza delle loro previsioni. La ragione principale è che una previsione migliorata porta a una migliore gestione delle scorte, una pianificazione della produzione più fluida e una più efficiente allocazione delle risorse.
Ciò dovrebbe ridurre i costi, minimizzare le rotture di stock, e ridurre gli eccessi di magazzino, il tutto aumentando la soddisfazione del cliente e generando un ethos di previsione e aziendale più inclusivo. Il processo si è dimostrato straordinariamente popolare, con il FVA che viene applicato in diverse note aziende in settori eccezionalmente competitivi, tra cui Intel, Yokohama Tire e Nestlé3.
Eseguire un’Analisi del Valore Aggiunto della Previsione
Eseguire un’analisi del valore aggiunto della previsione comporta diversi passaggi intuitivi, tipicamente una versione dettagliata dei seguenti:
-
Definire il processo identificando i singoli passaggi o componenti, ovvero l’elenco dei dipartimenti che verranno consultati, l’ordine della consultazione e i parametri specifici che ciascun contributore utilizzerà per modificare la previsione iniziale.
-
Generare una previsione di riferimento. Questo riferimento di solito assume la forma di una previsione ingenua. Viene generata anche una previsione statistica, come parte del normale processo di previsione all’interno dell’azienda, utilizzando lo stesso set di dati utilizzato per la generazione del riferimento. Questa previsione statistica serve da base per tutti gli aggiustamenti successivi.
-
Raccogliere informazioni dai contribuenti designati, attenendosi ai parametri esatti definiti nel primo passaggio. Questo potrebbe includere informazioni sulle tendenze di mercato, piani promozionali, vincoli operativi, ecc.
-
Calcolare il FVA per ciascun contributore confrontando l’accuratezza della previsione statistica prima e dopo l’input di quel contributore. A sua volta, l’accuratezza della previsione statistica viene confrontata con quella della semplice previsione di riferimento. I contributi che migliorano l’accuratezza della previsione ricevono FVA positivo, mentre quelli che la diminuiscono ricevono FVA negativo.
-
Ottimizzare migliorando o eliminando i contributi con FVA negativo, preservando o potenziando quelli con FVA positivo.
Questi passaggi costituiscono un processo continuo che viene migliorato iterativamente per ottenere una maggiore accuratezza delle previsioni. Il processo FVA, e come differisce da un processo di previsione tradizionale, è illustrato di seguito.
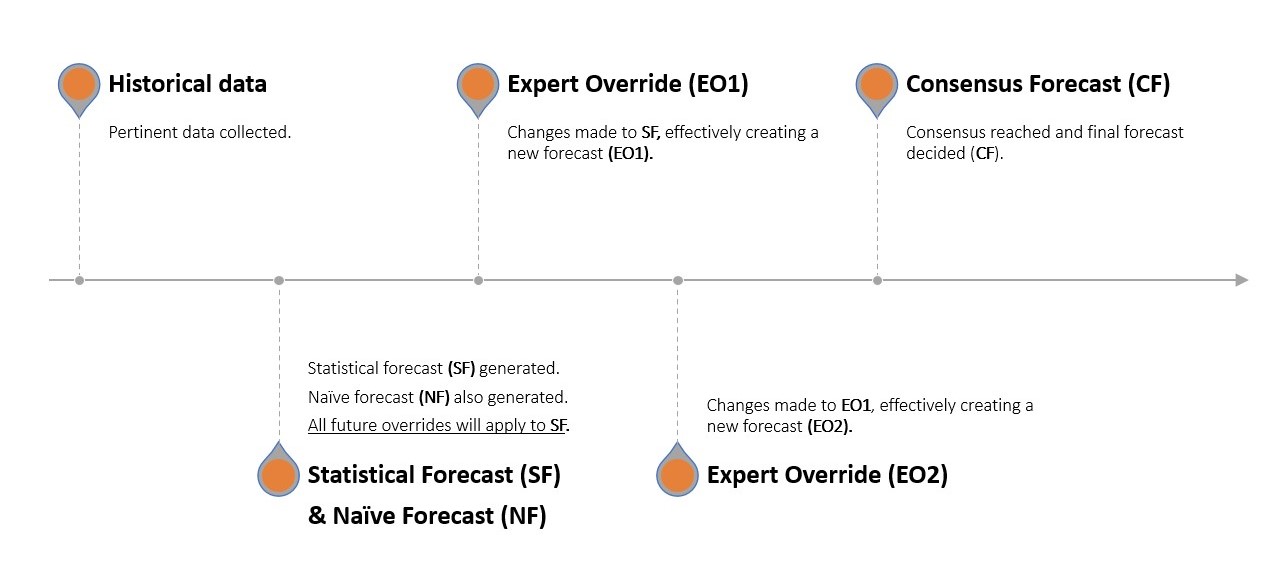
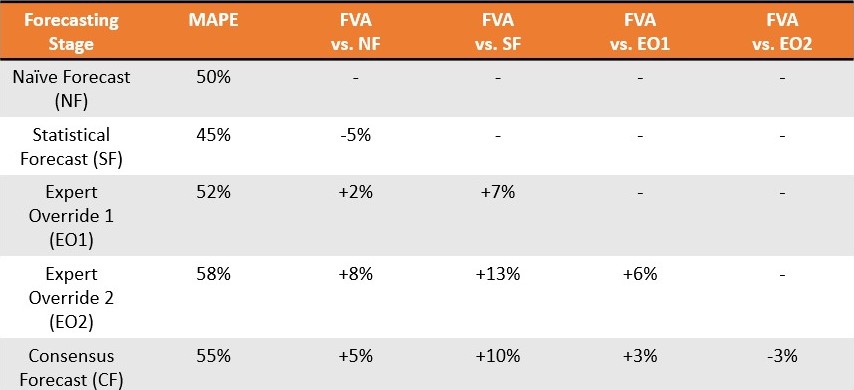
Consideriamo un venditore di mele. Paolo (Pianificazione della Domanda) informa la direzione che l’azienda ha venduto 8 mele in ciascuno degli ultimi 3 mesi. La previsione naïve dice che l’azienda venderà di nuovo 8 il prossimo mese, ma Paolo ha un software statistico avanzato che prevede la vendita di 10 mele (previsione statistica). Giovanni (Marketing) interviene e dice che intende lanciare uno slogan nuovo e accattivante questo mese6 e le vendite probabilmente saranno più alte questo mese grazie alla sua arguzia. Giorgio (Vendite) intende raggruppare le mele insieme e abbassare leggermente i prezzi, stimolando ulteriormente le vendite e aumentando la domanda. Riccardo (Operazioni) è inizialmente perplesso ma poi rivede la domanda prevista per riflettere un’imminente fermo della macchina cruciale per la selezione delle mele che crede avrà un impatto negativo sulla capacità dell’azienda di soddisfare la domanda. La previsione statistica è stata quindi modificata manualmente tre volte. I dipartimenti si riuniscono successivamente per raggiungere verbalmente una previsione di consenso.
Un mese dopo, l’azienda esegue un backtest per confermare quanto grande sia stata la delta7 in ciascun passaggio di questo relay di previsione, cioè quanto “sbagliata” sia stata la contribuzione di ciascun dipartimento. Questo non è difficile poiché ora possiedono i dati effettivi sulle vendite del mese precedente e Paolo può isolare, passo dopo passo, quanto errore è stato introdotto da Giovanni, Giorgio e Riccardo, rispettivamente, nonché dalla fase di previsione di consenso8.
La Prospettiva Matematica sul Valore Aggiunto della Previsione
Nel complesso, il valore aggiunto della previsione è un processo straordinariamente semplice e deliberatamente semplice. Contrariamente ai processi di previsione che richiedono una conoscenza avanzata di matematica e ragionamento statistico, il FVA “è un approccio di buon senso che è facile da capire. Esprime i risultati di fare qualcosa rispetto a non aver fatto nulla”3.
Esprimere i risultati di aver fatto qualcosa rispetto a non aver fatto nulla, tuttavia, richiede comunque un intervento matematico, che di solito assume la forma di una semplice serie temporale - il fondamento dei tradizionali metodi di previsione. L’obiettivo principale dell’analisi delle serie temporali è rappresentare in modo conveniente e intuitivo la domanda futura come un singolo valore operativo. Nel contesto del FVA, la serie temporale di base funge da placebo o controllo, rispetto al quale vengono confrontati tutti gli annullamenti dell’analista (dettagliati nella sezione precedente). Una serie temporale di base può essere generata attraverso vari metodi, comunemente includendo varie forme di previsione ingenua. Queste sono comunemente valutate utilizzando metriche come MAPE, MAD e MFE.
Scelta di una Previsione di Riferimento
La scelta della previsione di base varierà a seconda degli obiettivi o vincoli dell’azienda in questione.
-
Previsione Ingenua e Previsioni Stagionali Ingenua sono spesso scelte per la loro semplicità. Sono facili da calcolare e capire poiché si basano sull’assunzione che i dati precedenti si ripeteranno in futuro. Forniscono una base sensata in molti contesti, specialmente quando i dati sono abbastanza stabili o sembrano mostrare un chiaro pattern (tendenza, stagionalità, ecc.).
-
Random Walk e Random Walk Stagionale sono tipicamente utilizzati quando i dati mostrano una significativa casualità o variabilità, o quando sembra esserci un forte pattern stagionale che è anche soggetto a fluttuazioni casuali. Questi modelli aggiungono un elemento di imprevedibilità al concetto di previsione ingenua, nel tentativo di riflettere l’incertezza intrinseca della previsione della domanda futura.
Valutazione dei Risultati del Valore Aggiunto della Previsione
-
MFE (Errore Medio di Previsione) può essere utilizzato per valutare se una previsione tende a sovrastimare o sottostimare i risultati effettivi. Questo potrebbe essere una metrica utile in una situazione in cui è più costoso sovrastimare che sottostimare, o viceversa.
-
MAD (Deviazione Media Assoluta) e MAPE (Errore Percentuale Medio Assoluto) forniscono misure di accuratezza della previsione che considerano sia la sovrastima che la sottostima della domanda. Potrebbero essere utilizzati come indicatori di accuratezza quando è importante minimizzare le dimensioni complessive degli errori di previsione, indipendentemente dal fatto che comportino sovrastima o sottostima.
Anche se il MAPE è comunemente presente nelle fonti correlate al FVA, il consenso varia su quale configurazione di metriche di previsione utilizzare in un’analisi FVA2 4 9.
Limitazioni del FVA
Il valore aggiunto della previsione, nonostante il suo approccio inclusivo, nobili obiettivi e bassa barriera all’ingresso, è argomentabilmente soggetto a una vasta gamma di limitazioni e false premesse. Queste carenze spaziano su un’ampia gamma di campi, inclusi matematica, moderna teoria della previsione ed economia.
La Previsione non è Collaborativa
Il valore aggiunto della previsione si basa sull’idea che la previsione collaborativa sia positiva, nel senso che i multipli (e persino il consenso) annullamenti umani possono aggiungere valore positivo. Il FVA crede inoltre che questo valore di previsione positivo sia distribuito in tutta l’azienda, poiché i dipendenti di diversi dipartimenti possono tutti possedere preziose intuizioni sulla domanda di mercato futura.
Pertanto, il problema, secondo il FVA, è che questo approccio collaborativo comporta inefficienze fastidiose, come alcuni punti di contatto umani che contribuiscono a un valore negativo. Il FVA cerca quindi di scremare i collaboratori di previsione spreconi alla ricerca di quelli validi.
Purtroppo, l’idea che la previsione sia migliore come processo collaborativo e multi-departimentale è contraria a quanto dimostra la moderna previsione statistica, anche nelle situazioni di vendita al dettaglio.
Una vasta revisione della quinta competizione di previsione di Makridakis10 ha dimostrato che “tutti i 50 metodi migliori si basavano sull’ML (machine learning). Pertanto, M5 è la prima competizione M in cui tutti i metodi migliori erano sia metodi ML che migliori di tutti gli altri benchmark statistici e le loro combinazioni” (Makridakis et al., 2022)11. La competizione di accuratezza M5 si basava sulla previsione delle vendite utilizzando dati storici per la più grande azienda al dettaglio al mondo per ricavi (Walmart).
Infatti, secondo Makridakis et al. (2022), “il modello vincente [nel M5] è stato sviluppato da uno studente con poca conoscenza di previsione e poca esperienza nella costruzione di modelli di previsione delle vendite”11, mettendo così in dubbio quanto siano vitali le intuizioni di mercato dei dipartimenti disparati in un contesto di previsione.
Questo non significa che i modelli di previsione più complessi siano necessariamente desiderabili. Piuttosto, i modelli sofisticati spesso superano quelli semplicistici, e la previsione collaborativa del FVA è un approccio semplicistico a un problema complesso.
Ignora l’Incertezza Futura
Il FVA, come molti strumenti e tecniche legate alla previsione, presume che la conoscenza del futuro (in questo caso, la domanda) possa essere rappresentata sotto forma di serie temporale. Utilizza una previsione ingenua come riferimento (tipicamente una copia taglia e incolla delle vendite precedenti) e ha i collaboratori che arrotondano manualmente i valori su una previsione statistica. Questo è difettoso per due motivi.
Innanzitutto, il futuro, sia in generale che in termini di previsione, è irriducibilmente incerto. Pertanto, esprimerlo come un singolo valore è un approccio intrinsecamente sbagliato (anche se integrato con una formula di scorta di sicurezza). Di fronte all’incertezza irriducibile del futuro, l’approccio più sensato è determinare una gamma di valori futuri probabili, valutati rispetto al potenziale ritorno finanziario di ciascuno. Questo supera, da una prospettiva di gestione del rischio, il tentativo di identificare un singolo valore come per una serie temporale tradizionale, che ignora completamente il problema dell’incertezza futura.
In secondo luogo, le intuizioni (per quanto utili possano sembrare) dei collaboratori sono tipicamente del tipo non facilmente (se del caso) traducibili in una previsione a serie temporale. Considerate una situazione in cui un’azienda sa in anticipo che un concorrente sta per entrare sul mercato. In alternativa, immaginate un mondo in cui la conoscenza competitiva indica che il concorrente più agguerrito sta pianificando di lanciare una nuova linea di abbigliamento estivo impressionante. La proposta che questi tipi di intuizioni possano essere piegati collaborativamente da non specialisti in un singolo valore espresso in una serie temporale è fantasiosa.
In realtà, qualsiasi somiglianza con le vendite future effettive (valore aggiunto positivo) sarà completamente accidentale, nel senso che le sovrascritture umane (sia che si tratti di arrotondare la domanda verso l’alto o verso il basso) sono espressioni uguali dello stesso input difettoso. Una persona che contribuisce un valore negativo non è quindi più “giusta” o “sbagliata” - da un punto di vista logico - rispetto a chi contribuisce un valore positivo.
Al suo nucleo, FVA cerca di spingere proprietà tridimensionali (intuizioni umane) su una superficie bidimensionale (una serie temporale). Potrebbe sembrare corretto da un certo punto di vista, ma ciò non significa che lo sia veramente. Questo conferisce a FVA un’apparenza piuttosto fuorviante di rigore statistico.
Anche se l’azienda utilizza un processo di previsione tradizionale con minimi punti di contatto umano (come da Figura 1), se la previsione statistica sottostante analizzata da FVA è una serie temporale, l’analisi stessa è un esercizio di spreco.
Ironicamente Sprecatizio
Come dimostrazione unica di eccessiva fiducia e di decisioni di parte, FVA ha utilità. I premi Nobel sono stati assegnati sulla profondità, ampiezza e durata dei bias cognitivi nelle decisioni umane12 13, eppure è del tutto concepibile che alcuni team non accettino quanto difettosa sia di solito la sovrascrittura umana fino a quando non gliene viene data una dimostrazione enfatica.
Tuttavia, come strumento di gestione continuativo, FVA è intrinsecamente difettoso e probabilmente contraddittorio. Se le previsioni statistiche di uno sono superate da una previsione ingenua e da un intervento collaborativo, si dovrebbe davvero considerare la seguente domanda:
Perché le modelli statistici stanno fallendo?
Purtroppo, FVA non ha risposta a questa domanda perché fondamentalmente non è progettato per farlo. Non fornisce intuizioni su perché i modelli statistici potrebbero sottoperformare, semplicemente che sottoperformano. Quindi, FVA non è tanto uno strumento diagnostico quanto una lente d’ingrandimento.
Anche se una lente d’ingrandimento può essere utile, non fornisce intuizioni operative su quali siano effettivamente i problemi sottostanti del software di previsione statistica. Comprendere perché le previsioni statistiche sottoperformano ha un valore diretto e indiretto molto maggiore, ed è qualcosa su cui FVA non mette a fuoco.
Non solo il software FVA non fornisce questa importante intuizione, ma formalizza lo spreco in altri modi. Gilliland (2010) presenta una situazione teorica in cui una previsione di consenso è superata in 11 delle 13 settimane (tasso di fallimento dell'85%), con una media di errore del 13,8%. Piuttosto che giustificare una discontinuazione immediata, il consiglio è di
“portare queste scoperte alla vostra direzione e cercare di capire perché il processo di consenso ha questo effetto. Potete iniziare a indagare sulle dinamiche della riunione di consenso e sugli obiettivi politici dei partecipanti. Alla fine, la direzione deve decidere se il processo di consenso può essere corretto per migliorare l’accuratezza della previsione, o se dovrebbe essere eliminato.”2
In questo scenario, non solo il software FVA non diagnostica il problema sottostante delle prestazioni della previsione statistica, ma lo strato di strumentazione FVA aumenta semplicemente la burocrazia e l’allocazione delle risorse sezionando attività che manifestamente non contribuiscono valore.
Pertanto, installare uno strato di software FVA garantisce che si continui a ottenere immagini simili a bassa risoluzione di un problema in corso e indirizza risorse preziose per comprendere input difettosi che avrebbero potuto essere ignorati fin dall’inizio.
Questo, probabilmente, non è l’allocazione più prudente delle risorse aziendali che hanno usi alternativi.
Sovrastima il Valore dell’Accuratezza
Al suo nucleo, FVA presume che un aumento dell’accuratezza della previsione valga la pena perseguire isolatamente, e procede su questa base come se ciò fosse ovviamente vero. L’idea che un aumento dell’accuratezza della previsione sia desiderabile è comprensibilmente allettante, ma - dal punto di vista aziendale - presuppone che una maggiore accuratezza si traduca in una maggiore redditività. Questo non è affatto vero.
Questo non significa che una previsione accurata non valga la pena avere. Piuttosto, una previsione accurata dovrebbe essere strettamente legata a una prospettiva puramente finanziaria. Una previsione potrebbe essere più accurata del 40% ma il costo associato significa che l’azienda guadagna globalmente il 75% in meno di profitto. La previsione, sebbene notevolmente più accurata (valore aggiunto positivo), non ha ridotto i dollari di errore. Questo viola ciò che è il principio fondamentale del business: fare più soldi, o almeno non sprecarli.
In termini di FVA, è del tutto concepibile che il valore aggiunto positivo di un dipartimento sia una perdita netta per un’azienda, mentre il valore aggiunto negativo di un altro sia impercettibile. Sebbene Gilliland riconosca che alcune attività potrebbero aumentare l’accuratezza senza aggiungere valore finanziario, questo punto di vista non viene seguito fino alla sua conclusione logica: una prospettiva puramente finanziaria. Gilliland utilizza l’esempio di un analista che aumenta l’accuratezza della previsione di un punto percentuale:
“Il semplice fatto che un’attività di processo abbia un FVA positivo non significa necessariamente che debba essere mantenuta nel processo. Dobbiamo confrontare i benefici complessivi del miglioramento con il costo di quell’attività. L’accuratezza aggiuntiva sta aumentando il ricavo, riducendo i costi o rendendo i clienti più felici? In questo esempio, l’override dell’analista ha effettivamente ridotto l’errore di un punto percentuale. Ma dover assumere un analista per rivedere ogni previsione può essere costoso, e se il miglioramento è solo di un punto percentuale, vale davvero la pena?”2
In altre parole, un aumento del 1% potrebbe non valere la pena perseguire, ma un maggiore aumento dell’accuratezza della previsione potrebbe valere la pena. Questo presuppone che il valore finanziario sia legato a una maggiore accuratezza della previsione, il che non è necessariamente vero.
Pertanto, c’è una dimensione finanziaria inevitabile nella previsione che è al meglio sottovalutata in FVA (e, nel peggiore dei casi, appena notata). Questa prospettiva puramente finanziaria dovrebbe davvero essere il fondamento su cui si basa uno strumento mirato a ridurre gli sprechi.
Vulnerabile alla Manipolazione
FVA presenta anche un’opportunità evidente di manipolazione e di gioco, specialmente se l’accuratezza della previsione viene utilizzata come misura delle prestazioni dei dipartimenti. Questo è lo spirito della Legge di Goodhart, che afferma che una volta che un indicatore diventa la principale misura del successo (accidentalmente o deliberatamente), quell’indicatore cessa di essere utile. Questo fenomeno può spesso aprire la porta a fraintendimenti e/o manipolazioni.
Supponiamo che il team delle vendite abbia il compito di apportare aggiustamenti a breve termine alla previsione della domanda in base alle loro interazioni con i clienti. Il dipartimento vendite potrebbe vedere questa come un’opportunità per segnalare il proprio valore e iniziare a fare modifiche alla previsione anche quando non necessario, nel tentativo di dimostrare un FVA positivo. Potrebbero sovrastimare la domanda, facendosi apparire come se stessero generando valore, o ricalcolare la domanda al ribasso, facendosi apparire come se stessero correggendo una proiezione eccessivamente ottimistica da parte di un dipartimento precedente. In entrambi i casi, il dipartimento vendite potrebbe apparire più prezioso per l’azienda. Di conseguenza, il dipartimento marketing potrebbe sentirsi poi sotto pressione per apparire di generare valore, e il team inizia a fare modifiche altrettanto arbitrarie alla previsione (e così via).
In questo scenario, la misura FVA, originariamente pensata per migliorare l’accuratezza della previsione, diventa semplicemente un meccanismo politico per i dipartimenti segnalare valore piuttosto che aggiungerne, una critica che persino i sostenitori del FVA riconoscono9. Questi esempi dimostrano i potenziali pericoli della Legge di Goodhart quando si tratta di FVA14.
I sostenitori del FVA potrebbero sostenere che queste critiche psicologiche sono il punto principale del FVA, ovvero l’identificazione di input validi rispetto a quelli inutili. Tuttavia, dato che i pregiudizi associati all’override umano nella previsione sono così ben compresi oggigiorno, le risorse impiegate nel dissezionare questi input carichi di pregiudizi sarebbero meglio allocate a un processo che evita (per quanto possibile) tali input fin dall’inizio.
Soluzione Locale a un Problema Sistemico
Implicitamente, il tentativo di ottimizzare la previsione della domanda in isolamento presuppone che il problema della previsione della domanda sia separato da altri problemi della supply chain. In realtà, la previsione della domanda è complessa a causa dell’interazione di una vasta gamma di cause sistemiche della supply chain, tra cui l’influenza dei tempi di consegna dei fornitori lead times, interruzioni inaspettate della supply chain disruptions, scelte di allocazione di magazzino, strategie di pricing, ecc.
Tentare di ottimizzare la previsione della domanda in isolamento (alias, ottimizzazione locale) è un approccio sbagliato dato che i problemi a livello di sistema - le vere cause radici - non sono correttamente compresi e affrontati.
I problemi della supply chain - di cui la previsione della domanda è certamente uno - sono come persone che stanno su un trampolino: muovere una persona produce disequilibrio per tutti gli altri15. Per questo motivo, l’ottimizzazione olistica, end-to-end è migliore rispetto al tentativo di curare i sintomi in isolamento.
Punto di Vista di Lokad
Il valore aggiunto della previsione prende un’idea sbagliata (previsione collaborativa) e la rende sofisticata, vestendo l’idea sbagliata con strati di software non necessario e sperperando risorse che potrebbero avere utilizzi alternativi migliori.
Una strategia più sofisticata sarebbe guardare oltre l’intero concetto di accuratezza della previsione e optare invece per una politica di gestione del rischio che riduca i dollari di errore. In congiunzione con un approccio di previsione probabilistico, questa mentalità si allontana dai KPI arbitrari - come aumentare l’accuratezza della previsione - e considera la totalità dei propri driver economici, vincoli e potenziali shock della supply chain nelle decisioni di inventario. Questi tipi di vettori di rischio (e spreco) non possono essere efficacemente quantificati (ed eliminati) da uno strumento che sfrutta una prospettiva collaborativa a serie temporali, come quella trovata nel valore aggiunto della previsione.
Inoltre, separando la previsione della domanda dall’ottimizzazione generale della supply chain, il FVA (forse involontariamente) aumenta la complessità accidentale del processo di previsione della domanda. La complessità accidentale è sintetica e deriva dall’accumulo graduale di rumore non necessario - di solito di origine umana - in un processo. Aggiungere fasi e software ridondanti al processo di previsione, come fa il FVA, è un esempio lampante di complessità accidentale e può rendere il problema significativamente più complesso.
La previsione della domanda è un problema intenzionalmente complesso, che è un compito intrinsecamente enigmatico e intensivo in termini di risorse. Questa complessità è un tratto immutabile del problema e rappresenta una classe di sfide molto più preoccupante rispetto alle questioni accidentalmente complesse. Per questo motivo, è meglio evitare tentativi di soluzioni che semplificano e travisano fondamentalmente il problema in questione16. Per parafrasare il retorica medica della letteratura FVA, questa è la differenza tra curare una malattia sottostante e trattare costantemente i sintomi man mano che si presentano17.
In breve, il FVA si colloca nello spazio tra la teoria all’avanguardia della supply chain e la consapevolezza del pubblico al riguardo. Si consiglia una maggiore istruzione sulle cause sottostanti dell’incertezza della domanda - e le sue radici nell’evoluzione della disciplina della supply chain.
Note
-
Forecast Value Added e Forecast Value Add sono utilizzati per fare riferimento allo stesso strumento di analisi delle previsioni. Anche se entrambi i termini sono ampiamente utilizzati, c’è una preferenza trascurabile in Nord America per quest’ultimo (secondo Google Trends). Tuttavia, Michael Gilliland si riferisce esplicitamente ad esso come Forecast Value Added in tutto The Business Forecasting Deal - il libro (e l’autore) più comunemente citato nelle discussioni su FVA. ↩︎
-
Gilliland, M. (2010). The Business Forecasting Deal, Wiley. ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
-
Gilliland, M. (2015). Forecast Value Added Analysis: Step by Step, SAS. ↩︎ ↩︎ ↩︎
-
Chybalski, F. (2017). Forecast value added (FVA) analysis as a means to improve the efficiency of a forecasting process, Operations Research and Decisions. ↩︎ ↩︎
-
La tabella del modello è stata adattata da Schubert, S., & Rickard, R. (2011). Using forecast value added analysis for data-driven forecasting improvement. IBF Best Practices Conference. Il rapporto a gradini compare anche in The Business Deal di Gilliland. ↩︎
-
John ha optato per “Tutto ciò di cui hai bisogno sono mele” anziché il leggermente più verboso “Possiamo risolverlo… con mele”. ↩︎
-
Nel contesto attuale, delta è una misura di quanto errore è stato introdotto nella previsione da ciascun membro del processo di previsione. Questo utilizzo del termine differisce leggermente da delta nel trading di opzioni, che misura il tasso di variazione del prezzo di un’opzione rispetto al prezzo di un attivo sottostante. Entrambi sono espressioni complessive di volatilità, ma il diavolo è nei dettagli. ↩︎
-
Si invita il lettore a sostituire la previsione della domanda di mele con la previsione della domanda per una vasta rete globale di negozi, sia online che offline, tutti dotati di un catalogo con 50.000 SKU. La difficoltà, non sorprendentemente, aumenta esponenzialmente. ↩︎
-
Le competizioni di previsione di Spyros Makridakis, conosciute colloquialmente come M-competitions, si svolgono dal 1982 e sono considerate l’autorità principale sulle metodologie di previsione all’avanguardia (e talvolta sanguinanti). ↩︎
-
Makridakis, S., Spiliotis, E., & Assimakopolos, V., (2022). M5 Accuracy Competition: Results, Findings, and Conclusions. Vale la pena menzionare che non tutti i 50 metodi più performanti erano basati su ML. C’è stata una eccezione significativa… Lokad. ↩︎ ↩︎
-
Il lavoro (sia individualmente che collettivamente) di Daniel Kahneman, Amos Tversky e Paul Slovic rappresenta un raro esempio di ricerca scientifica di rilievo che ottiene un plauso diffuso. Il libro del 2011 di Kahneman Pensieri lenti e veloci - che dettaglia gran parte della sua ricerca premiata con il Nobel del 2002 - è un testo di riferimento nella divulgazione scientifica popolare e tratta i pregiudizi nella presa di decisioni in misura superiore a quanto trattato in questo articolo. ↩︎
-
Karelse, J. (2022), Storie del Futuro, Forbes Books. Karelse dedica un intero capitolo alla discussione dei pregiudizi cognitivi in un contesto di previsione. ↩︎
-
Questo è un punto non banale. I dipartimenti hanno tipicamente KPI che devono raggiungere, e la tentazione di manipolare le previsioni per soddisfare le proprie esigenze è comprensibile e prevedibile (gioco di parole inteso). Per contestualizzare, Vandeput (2021, citato in precedenza) osserva che la dirigenza - l’ultima tappa sulla giostra del FVA - potrebbe distortamente influenzare la previsione per accontentare gli azionisti e/o i membri del consiglio. ↩︎
-
Questa analogia è tratta dalla psicologa Carol Gilligan. Gilligan l’ha originariamente utilizzata nel contesto dello sviluppo morale dei bambini e dell’interrelazione dell’azione umana. ↩︎
-
Vale la pena piantare un’asta qui. Soluzioni è un po’ fuorviante nel contesto della complessità intenzionale. Compromessi - disponibili in versioni migliori o peggiori - rifletterebbero meglio l’equilibrio delicato associato all’affrontare problemi intenzionalmente complessi. Non si può veramente risolvere un problema in cui due o più valori sono in completa opposizione. Un esempio è la lotta tra la riduzione dei costi e il raggiungimento di livelli di servizio più elevati. Dato che il futuro è irriducibilmente incerto, non c’è modo di prevedere la domanda con un’accuratezza del 100%. Si può, tuttavia, raggiungere un livello di servizio del 100% - se questo è il principale problema aziendale - semplicemente mantenendo in magazzino molto più inventario di quanto si possa mai vendere. Ciò comporterebbe enormi perdite, quindi le aziende, implicitamente o meno, accettano che ci sia un compromesso inevitabile tra risorse e livello di servizio. Pertanto, il termine “soluzione” inquadra impropriamente il problema come uno che è in grado di essere risolto piuttosto che attenuato. Consultare Economia di Base di Thomas Sowell per un’analisi approfondita del tira e molla tra compromessi rivali. ↩︎
-
In The Business Forecasting Deal, Gilliland paragona FVA a un trial di farmaci con previsioni naive che agiscono come il placebo. ↩︎