Business Intelligence (BI)
BI (Business Intelligence) si riferisce a una classe di software aziendale dedicato alla produzione di rapporti analitici basati principalmente sui dati transazionali raccolti attraverso i vari sistemi aziendali utilizzati dall’azienda per operare. L’obiettivo del BI è offrire capacità di reporting self-service agli utenti che non sono specialisti IT. Queste capacità di self-service possono variare dall’aggiustamento dei parametri su rapporti esistenti alla creazione di nuovi rapporti completi. La maggior parte delle grandi aziende ha almeno un sistema BI in funzione sopra i propri sistemi transazionali, che spesso include un ERP.
Origine e motivazione
Il moderno rapporto analitico è emerso con i primi previsionisti economici1 2, prevalentemente negli Stati Uniti, all’inizio del XX secolo. Questa prima iterazione si è rivelata estremamente popolare, ricevendo attenzione dalla stampa mainstream e una vasta circolazione. Questa popolarità ha dimostrato un forte interesse per rapporti quantitativi ad alta densità di informazioni. Negli anni ‘80, molte grandi aziende hanno iniziato a conservare le loro transazioni commerciali come registri elettronici, archiviati in database transazionali, sfruttando tipicamente alcune prime soluzioni ERP. Queste soluzioni ERP erano principalmente intese a razionalizzare i processi esistenti, migliorando la produttività e l’affidabilità. Tuttavia, molti hanno compreso l’enorme potenziale inutilizzato di questi registri e, nel 1983, SAP ha introdotto il linguaggio di programmazione ABAP3, dedicato alla generazione di rapporti basati sui dati raccolti all’interno dell’ERP stesso.
Tuttavia, i sistemi di database relazionali, come solitamente venduti negli anni ‘80, presentavano due limitazioni principali per quanto riguarda la produzione di rapporti analitici. In primo luogo, la progettazione dei rapporti doveva essere effettuata da specialisti IT altamente addestrati. Ciò rendeva il processo lento ed costoso, limitando gravemente la diversità dei rapporti che potevano essere introdotti. In secondo luogo, la generazione dei rapporti era molto gravosa per l’hardware di calcolo4. I rapporti potevano, di solito, essere prodotti solo durante la notte (e in batch), quando le operazioni aziendali erano cessate. In qualche misura, ciò rifletteva le limitazioni dell’hardware di calcolo dell’epoca, ma rifletteva anche le limitazioni software.
All’inizio degli anni ‘90, i progressi dell’hardware di calcolo hanno permesso l’emergere di una diversa classe di soluzioni software4, soluzioni Business Intelligence. Il costo della RAM (memoria ad accesso casuale) era diminuito costantemente, mentre la sua capacità di archiviazione era aumentata costantemente. Di conseguenza, archiviare una versione specializzata e più compatta dei dati aziendali in memoria (in RAM) per un accesso immediato è diventata una soluzione fattibile, sia dal punto di vista tecnologico che economico. Questi sviluppi hanno affrontato le due principali limitazioni dei sistemi di reporting implementati un decennio prima: le nuove interfacce software front-end erano molto più accessibili ai non specialisti; e i nuovi software back-end - con tecnologie OLAP (discusse di seguito) - hanno eliminato alcuni dei più grandi vincoli IT. Grazie a questi progressi, alla fine del decennio, le soluzioni BI erano diventate diffuse tra le grandi aziende.
Con il progresso dell’hardware informatico, una nuova generazione di strumenti BI è emersa5 alla fine degli anni 2000. I sistemi di database relazionali degli anni ‘80, che erano incapaci di produrre rapporti in modo conveniente, sono diventati, negli anni 2000, sempre più capaci di contenere l’intera storia transazionale di un’azienda in RAM. Di conseguenza, le query analitiche complesse potevano essere completate in pochi secondi senza un back-end OLAP dedicato. Di conseguenza, l’attenzione delle soluzioni BI si è spostata sul front-end, offrendo interfacce utente web ancora più accessibili - prevalentemente SaaS (software-as-a-service) - e caratterizzate da dashboard sempre più interattive che sfruttavano la versatilità del back-end relazionale.
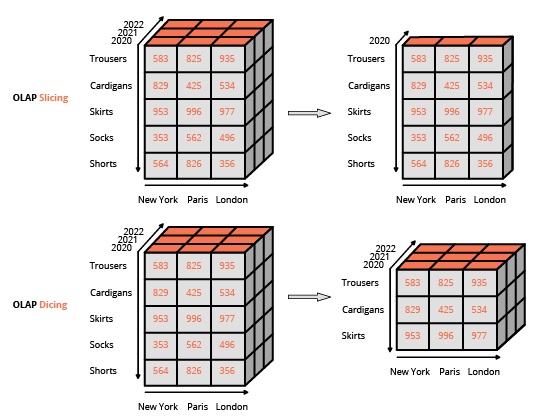
OLAP e cubi multidimensionali
OLAP sta per online analytical processing. OLAP è associato alla progettazione del back-end di una soluzione BI. Il termine, coniato nel 1993 da Edgar Codd, federava una serie di idee di progettazione del software6, la maggior parte delle quali risalenti agli anni ‘90, con alcune che risalgono agli anni ‘60. Queste idee di progettazione sono state fondamentali nell’emergere di BI come una classe distinta di prodotti software negli anni ‘90. OLAP ha affrontato la sfida di essere in grado di produrre rapporti analitici freschi in modo tempestivo, anche quando la quantità di dati coinvolti nella produzione del rapporto era troppo grande per essere elaborata rapidamente.
La tecnica più semplice per produrre un rapporto analitico fresco prevede di leggere i dati almeno una volta. Tuttavia, se il set di dati è così grande7 che leggerlo nella sua interezza richiede ore (se non giorni), allora la produzione di un rapporto fresco richiederà anche ore o giorni. Pertanto, per produrre un rapporto aggiornato in pochi secondi, la tecnica non può comportare la rilettura del set di dati completo ogni volta che viene richiesto un aggiornamento del rapporto.
OLAP propone di sfruttare strutture dati più piccole e compatte - che riflettono i rapporti di interesse. Queste specifiche strutture dati sono destinate ad essere aggiornate incrementalmente man mano che diventano disponibili dati più recenti. Di conseguenza, quando viene richiesto un rapporto fresco, il sistema BI non deve rileggere l’intero set di dati storici, ma solo la struttura dati compatta che contiene tutte le informazioni necessarie per generare il rapporto. Inoltre, se la struttura dati è sufficientemente piccola, può essere mantenuta in memoria (in RAM) e quindi essere accessibile più velocemente rispetto alla memoria persistente utilizzata per i dati transazionali.
Considera il seguente esempio: immagina una rete di vendita al dettaglio che gestisce 100 ipermercati. Il CFO desidera un rapporto con le vendite totali in euro per negozio al giorno negli ultimi 3 anni. I dati storici grezzi delle vendite degli ultimi 3 anni rappresentano più di 1 miliardo di righe di dati (ogni codice a barre scansionato in ogni negozio per questo periodo) e più di 50 GB nel loro formato tabellare grezzo. Tuttavia, una tabella con 100 colonne (1 per ipermercato) 1095 righe (3 anni * 365 giorni) totalizza meno di 0,5 MB (a un tasso di 4 byte per numero). Inoltre, ogni volta che si verifica una transazione, le celle corrispondenti nella tabella possono essere aggiornate di conseguenza. Creare e mantenere una tale tabella illustra come appare un sistema OLAP sotto il cofano.
Le strutture dati compatte descritte sopra assumono di solito la forma di un cubo OLAP, chiamato anche cubo multidimensionale. Le celle esistono nel cubo all’intersezione delle dimensioni discrete che definiscono la struttura complessiva del cubo. Ogni cella contiene una misura (o valore) estratto dai dati transazionali originali, spesso indicato come tabella dei fatti. Questa struttura dati è simile ad array multidimensionali che si trovano nella maggior parte dei linguaggi di programmazione mainstream. Il cubo OLAP si presta a efficienti operazioni di proiezione o aggregazione lungo le dimensioni (come somma e media), a condizione che il cubo rimanga sufficientemente piccolo da adattarsi alla memoria del computer.
Reporting interattivo e visualizzazione dei dati
Rendere le capacità di reporting accessibili agli utenti finali che non erano specialisti IT è stato un fattore chiave nell’adozione degli strumenti BI. Come tale, la tecnologia ha adottato un design WYSIWYG (what-you-see-is-what-you-get), basandosi su interfacce utente ricche. Questo approccio differisce dall’approccio usuale per interagire con un database relazionale, che consiste nella composizione di query utilizzando un linguaggio specializzato (come SQL). L’interfaccia usuale per manipolare un cubo OLAP è un’interfaccia a matrice, come le tabelle pivot in un programma di fogli di calcolo, che consente agli utenti di applicare filtri (chiamati slice and dice nel gergo BI) e eseguire aggregazioni (media, minimo, massimo, somma, ecc.).
Ad eccezione dell’elaborazione di set di dati particolarmente grandi, la necessità di cubi OLAP è diminuita alla fine degli anni 2000 parallelamente ai grandi progressi compiuti nell’hardware di elaborazione. Sono stati introdotti nuovi strumenti BI “sottili” con un focus esclusivo sul front-end. Gli strumenti BI sottili sono stati progettati principalmente per interagire con database relazionali, a differenza dei loro predecessori “spessi” che sfruttavano back-end integrati con cubi OLAP. Questa evoluzione è stata possibile perché le prestazioni dei database relazionali, in quel periodo, consentivano di eseguire query complesse sull’intero set di dati in pochi secondi, a condizione che il set di dati rimanesse al di sotto di una certa dimensione. Gli strumenti BI sottili possono essere visti come editor WYSIWYG unificati per i vari dialetti SQL che supportavano. (Infatti, sotto il cofano, questi strumenti BI generano query SQL.) La principale sfida tecnica era l’ottimizzazione delle query generate, al fine di ridurre al minimo il tempo di risposta del database relazionale sottostante.
Le capacità di visualizzazione dei dati degli strumenti BI erano principalmente una questione di presentazione dei dati sul lato client, sia attraverso un’app desktop che web. Le capacità di presentazione sono progredite costantemente fino agli anni 2000, quando l’hardware dell’utente finale (ad esempio, workstation e notebook) ha iniziato a superare di gran lunga (dal punto di vista computazionale) ciò che era necessario per scopi di visualizzazione dei dati. Oggi, anche le visualizzazioni dei dati più elaborate sono processi poco impegnativi, oscurati in scala dal consumo di risorse di calcolo associate all’estrazione e trasformazione dei dati sottostanti che vengono visualizzati.
L’impatto organizzativo dei sistemi BI
Sebbene la facilità di accesso sia stata un fattore determinante per l’adozione della maggior parte degli strumenti BI, navigare nel panorama dei dati delle grandi aziende è difficile, anche solo a causa della grande diversità di dati disponibili. Inoltre, anche se lo strumento BI è abbastanza accessibile, la logica di reporting che le aziende implementano attraverso gli strumenti BI tende a riflettere la complessità del business e, di conseguenza, la logica stessa può essere molto meno accessibile rispetto allo strumento che supporta la sua esecuzione.
Di conseguenza, l’adozione degli strumenti BI ha portato - per la maggior parte delle grandi aziende - alla creazione di team di analisi dedicati, che di solito operano come funzione di supporto insieme al dipartimento IT. Come previsto dalla legge di Parkinson, il lavoro si espande per riempire il tempo disponibile per il completamento; questi team tendono ad espandersi nel tempo insieme al numero di report generati, indipendentemente dai benefici ottenuti (percepiti o effettivi) dall’azienda dall’accesso a tali report.
Limiti tecnici degli strumenti BI
Come spesso accade, c’è un compromesso tra i vantaggi quando si tratta di strumenti BI, il che significa che una maggiore facilità di accesso comporta un limite di espressività; in questo caso, le trasformazioni applicate ai dati sono limitate a una classe relativamente ristretta di filtri e aggregazioni. Questa è la prima grande limitazione, poiché molte - se non la maggior parte - delle domande aziendali non possono essere affrontate con questi operatori (ad esempio, qual è il rischio di churn di un cliente?). Naturalmente, è possibile introdurre operatori avanzati nell’interfaccia utente del BI, tuttavia tali funzionalità “avanzate” vanificano 8 lo scopo iniziale di rendere lo strumento facilmente accessibile agli utenti non tecnici. Pertanto, progettare query avanzate sui dati non è diverso dalla creazione di software, un compito che si rivela intrinsecamente difficile. A titolo di prova aneddotica, la maggior parte degli strumenti BI offre la possibilità di scrivere query “grezze” (tipicamente in SQL o in un dialetto simile a SQL), tornando al percorso tecnico che lo strumento avrebbe dovuto eliminare.
La seconda grande limitazione è le prestazioni. Questa limitazione si presenta in due varianti distinte per gli strumenti BI leggeri e pesanti, rispettivamente. Gli strumenti BI leggeri includono tipicamente una logica sofisticata per ottimizzare le query al database che generano. Tuttavia, questi strumenti sono limitati dalle prestazioni che il database di back-end può offrire. Una query apparentemente semplice può rivelarsi inefficiente da eseguire, portando a tempi di risposta lunghi. Un ingegnere di database può certamente modificare e migliorare il database per affrontare questa problematica. Tuttavia, anche in questo caso, questa soluzione vanifica l’obiettivo iniziale di mantenere lo strumento BI accessibile agli utenti non tecnici.
Gli strumenti BI pesanti hanno le loro prestazioni limitate dal design dei cubi OLAP stessi. Innanzitutto, la quantità di RAM necessaria per mantenere un cubo multidimensionale in memoria aumenta rapidamente all’aumentare delle dimensioni del cubo. Anche un numero moderato di dimensioni (ad esempio, 10) può causare gravi problemi legati all’occupazione di memoria del cubo. Più in generale, i design in-memory (con i cubi OLAP come i più frequenti) solitamente soffrono di problemi legati alla memoria.
Inoltre, il cubo è una rappresentazione parziale dei dati transazionali originali: nessuna analisi eseguita con il cubo può recuperare informazioni che sono state perse in primo luogo. Ricordiamo l’esempio dell’ipermercato. In un tale scenario, i carrelli della spesa non possono essere rappresentati in un cubo. Pertanto, le informazioni sul “acquistato insieme” vengono perse. Il design complessivo del “cubo” OLAP limita notevolmente quali dati possono essere rappresentati; tuttavia, questa limitazione è precisamente ciò che rende possibile la proprietà “online” in primo luogo.
Limiti aziendali degli strumenti BI
L’introduzione degli strumenti BI in un’azienda è meno trasformativa di quanto possa sembrare. In poche parole, produrre numeri, di per sé, non ha alcun valore per l’azienda se non è associata alcuna azione. Il design stesso degli strumenti BI enfatizza una produzione “illimitata” di report, ma il design non supporta alcun effettivo percorso d’azione. Infatti, nella maggior parte delle situazioni, la scarsa espressività degli strumenti BI si rivela troppo limitante quando si tratta di automatizzare qualsiasi cosa basata sui report del BI.
Inoltre, lo strumento BI tende ad accentuare le tendenze burocratiche delle grandi aziende. Le prove aneddotiche, i numeri approssimativi e il buon senso sono spesso sufficienti per stabilire le priorità di un’azienda. Tuttavia, l’esistenza di uno strumento analitico a servizio proprio - come il BI - offre ampie opportunità di procrastinare e confondere le acque con un flusso incessante di metriche discutibili e non azionabili.
Gli strumenti BI sono vulnerabili ai problemi di progettazione per commissione in cui le idee di tutti vengono incluse nel progetto. La natura a servizio proprio dello strumento enfatizza un approccio estremamente inclusivo quando si tratta di introdurre nuovi report. Di conseguenza, la complessità del panorama dei report tende a crescere nel tempo, indipendentemente dalla complessità aziendale che tali report dovrebbero riflettere. Il termine metriche di vanità è diventato ampiamente utilizzato per riflettere metriche - di solito implementate attraverso uno strumento BI - come queste che non contribuiscono al risultato finale di un’azienda.
Punto di vista di Lokad
Considerando le capacità dell’hardware di calcolo moderno, utilizzare un sistema di reportistica per produrre 1 milione di numeri al giorno è facile; produrre 10 numeri al giorno degni di lettura è difficile. Mentre uno strumento BI utilizzato in piccole dosi è una cosa positiva per la maggior parte delle aziende, in dosi più elevate diventa un veleno.
In pratica, ci sono solo un numero limitato di intuizioni che possono essere ottenute dal BI. L’introduzione di sempre più report comporta un ritorno decrescente in termini di nuove (o migliorate) intuizioni ottenute attraverso ogni report aggiuntivo. Ricorda, la profondità dell’analisi dei dati accessibile tramite uno strumento BI è limitata per design, poiché le query devono rimanere facilmente accessibili anche a non specialisti tramite l’interfaccia utente.
Inoltre, anche quando viene acquisita una nuova intuizione attraverso i dati, ciò non implica che l’azienda possa trasformarla in qualcosa di azionabile. Il BI è, nel suo nucleo, una tecnologia di reporting: non enfatizza alcuna chiamata all’azione per l’azienda. Il paradigma del BI non è orientato all’automazione delle decisioni aziendali (neanche quelle banali).
Le funzionalità della piattaforma Lokad includono ampie capacità di reportistica personalizzata, come il BI. Tuttavia, a differenza del BI, Lokad è mirato all’ottimizzazione delle decisioni aziendali, più specificamente quelle relative alla supply chain. In pratica, consigliamo di affidare a un Supply Chain Scientist la progettazione e successiva manutenzione della ricetta numerica che genera - attraverso Lokad - le decisioni sulla supply chain di interesse.
Note
-
Fortune Tellers: The Story of America’s First Economic Forecasters, di Walter Friedman (2013). ↩︎
-
A Selection of Early Forecasting & Business Charts, di Walter Friedman (2014) (PDF) ↩︎
-
ABAP è un linguaggio di programmazione rilasciato da SAP nel 1983 che sta per Allgemeiner Berichts-Aufbereitungs-Prozessor, ovvero “processore generale di preparazione dei report” in tedesco. Questo linguaggio è stato introdotto come precursore dei sistemi BI per integrare l’ERP (anch’esso chiamato SAP) con funzionalità di reportistica. L’obiettivo di ABAP era quello di alleviare l’onere ingegneristico associato all’implementazione di report personalizzati. Negli anni ‘90, ABAP è stato riproposto come linguaggio di configurazione ed estensione per l’ERP stesso. Il linguaggio è stato anche rinominato in inglese come Advanced Business Application Programming per riflettere questo cambio di focus. ↩︎
-
BusinessObjects, fondata nel 1990 e acquisita da SAP nel 2008, è l’archetipo delle soluzioni BI emerse negli anni ‘90. ↩︎ ↩︎
-
Tableau, fondata nel 2003 e acquisita da Salesforce nel 2019, è l’archetipo delle soluzioni BI emerse negli anni 2000. ↩︎
-
Le origini dei prodotti OLAP di oggi, Nigel Pendse, ultimo aggiornamento agosto 2007, ↩︎
-
L’hardware di elaborazione è progredito costantemente dagli anni ‘50. Tuttavia, ogni volta che è diventato più economico elaborare più dati, è diventato anche più economico archiviare più dati. Di conseguenza, dagli anni ‘70, la quantità di dati aziendali è cresciuta quasi alla stessa velocità delle capacità dell’hardware di elaborazione. Pertanto, l’idea di “troppi dati” è in gran parte un obiettivo in movimento. ↩︎
-
Alla fine degli anni ‘90 e all’inizio degli anni 2000, molte aziende di software hanno cercato - e fallito - di sostituire i linguaggi di programmazione con strumenti visivi. Vedi anche, Lego Programming di Joel Spolsky, dicembre 2006 ↩︎