Analyse ABC XYZ (Les Stocks)
L’analyse ABC XYZ, tout comme son prédécesseur l’analyse ABC, est un outil de catégorisation visant à identifier les produits les plus performants dans son catalogue afin de déterminer les niveaux de service et de sécurité appropriés des stocks. Contrairement à l’analyse ABC, qui se concentre exclusivement sur un critère unique (généralement le volume des ventes ou le chiffre d’affaires), l’analyse ABC XYZ tente également de quantifier une deuxième dimension (l’incertitude ou la volatilité de la demande). Malgré peut-être une image légèrement plus précise des performances, l’analyse ABC XYZ reste une application naïve des principes mathématiques sous-jacents et ne fait que renforcer la bureaucratie et l’instabilité. Elle conserve également toutes les limites d’une analyse ABC classique, mais offre sans doute une plus grande illusion de sécurité grâce à des tours de passe-passe mathématiques.
Réaliser une analyse ABC XYZ
Alors qu’une analyse ABC vise à décomposer financièrement un ensemble de SKU en trois classes sur une période de temps,1 fournissant ainsi à un praticien de la supply chain une répartition des SKU selon leur importance financière, l’analyse ABC XYZ prétend aller encore plus loin. Elle tente de comprendre et de quantifier la variance de la demande (ou la volatilité) pour chaque SKU sur la période observée, et de fusionner les classes A, B et C classiques avec les classes supplémentaires X, Y et Z. En termes simples, la variance de la demande est une mesure de la variation de la demande au cours de la période observée. Cela peut refléter des périodes de demande extrêmement élevée (ou faible) inattendues et/ou isolées, ou une difficulté globale soutenue à prédire le nombre d’unités d’un SKU réellement nécessaires (ou toute autre raison pour laquelle la demande aurait pu fluctuer sur la période). Ces variations sont ce que les désignations X, Y et Z sont censées capturer.
Sous cette nouvelle rubrique à neuf catégories, les SKU de classe X sont les plus stables (ils connaissent la plus faible variance de la demande), les classes Y sont quelque peu stables (elles connaissent une variance de la demande modérée) et les classes Z sont les plus instables (elles connaissent la plus forte variance de la demande). En s’appuyant sur l’analyse ABC classique, un praticien de la supply chain se voit présenter une répartition apparemment plus nuancée de son catalogue sur la période, où les SKU sont analysés selon deux fois plus de dimensions.
Pour traiter cette nouvelle classification, un praticien de la supply chain suit les mêmes étapes initiales que l’analyse ABC classique. Une fois cette étape terminée, on passe à la partie XYZ de l’analyse, où l’on a besoin de :
- Le nombre souhaité de classes de variance de la demande : généralement limité à 3, bien que cela soit flexible.
- Un seuil de séparation pour chaque classe : entièrement à la discrétion du praticien de la supply chain. Un exemple pourrait être <=10% pour la classe X, >10-25% pour la classe Y et >25% pour la classe Z.
- La moyenne pour chaque SKU sur la période observée : facilement calculée dans n’importe quel tableur.
- L’écart type et le coefficient de variation pour chaque SKU : également facilement calculés dans n’importe quel tableur.
L’écart type, dans le contexte d’une année de données, représente généralement la différence entre les ventes d’un mois donné et la moyenne mensuelle globale de l’année. Une fois que le praticien de la supply chain dispose de ces informations, il peut calculer le coefficient de variation (CV). Également connu sous le nom d’écart type relatif, le CV est une valeur en pourcentage qui indique dans quelle mesure un point de données donné s’éloigne de la moyenne, ce qui représente dans ce cas l’ampleur des fluctuations des ventes d’un SKU sur la période observée (par rapport à la moyenne). Cette valeur en pourcentage est obtenue en divisant l’écart type par la moyenne.
Une fois le CV calculé, le praticien de la supply chain classe les SKUs dans leurs classes X, Y et Z respectives en fonction de leurs seuils prédéterminés. Cela donne une matrice à neuf catégories où les SKUs sont triés en fonction de leur chiffre d’affaires et de la variance de la demande.
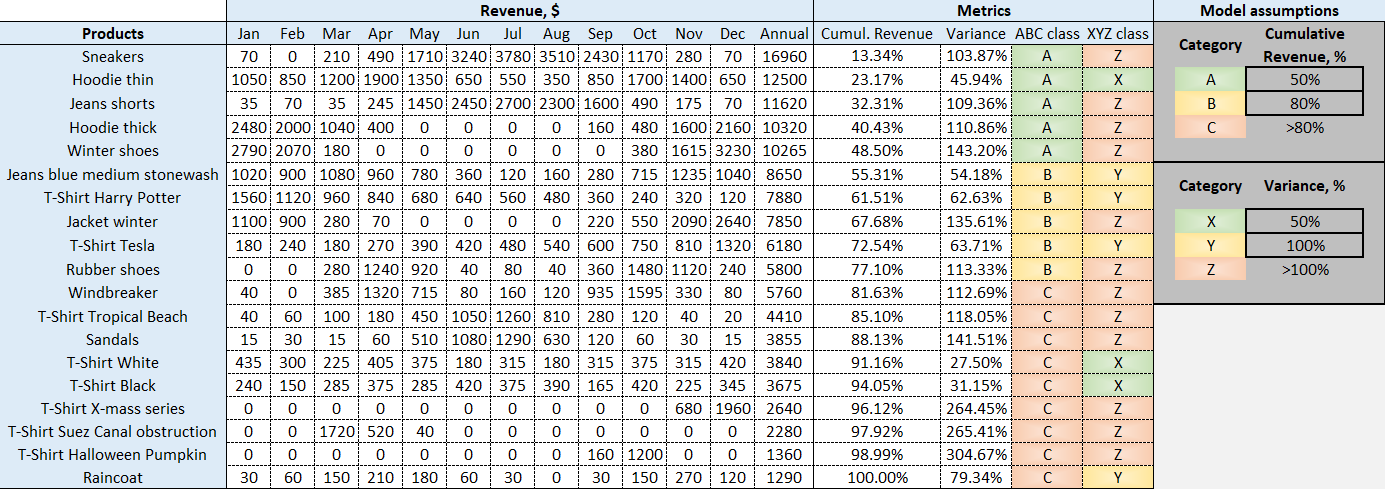
Figure 1. Une analyse ABC XYZ modèle, telle qu'elle apparaît dans la feuille de calcul Excel téléchargeable. Pour des calculs explicites, veuillez consulter les formules des colonnes pertinentes.
Téléchargez la feuille de calcul Excel : abc-xyz-analysis-tool.xlsx
La perspective mathématique sur ABC et ABC XYZ
D’un point de vue purement mathématique, que ce soit implicitement ou explicitement, les analyses ABC et ABC XYZ tentent toutes deux de tirer parti du concept de moments, qui est un ensemble infini de mesures quantitatives visant à cartographier une fonction. Dans le contexte actuel, la fonction est une distribution des données de vente, et les moments d’intérêt sont les deux premiers : la moyenne pour l’analyse ABC traditionnelle ; la moyenne et la variance pour l’analyse ABC XYZ. En ce qui concerne l’analyse ABC, étant donné qu’elle se concentre uniquement sur le premier moment (la moyenne), il serait plus précis de qualifier cette méthode de segmentation de moyenne mobile. Fondamentalement, il n’y a aucune tentative d’identifier l’incertitude de la demande. Pour cette raison, l’analyse ABC XYZ tente d’utiliser le deuxième moment (la variance) pour quantifier cette incertitude. Cela fait de l’analyse ABC XYZ une méthode de segmentation de moyenne mobile-variance. Contrairement à la moyenne, qui est largement comprise, la variance est un peu moins courante. En résumé, elle représente la dispersion d’un ensemble de valeurs - ici, les données de ventes mensuelles moyennes - par rapport à la valeur moyenne de l’ensemble. ABC XYZ utilise cet outil mathématique supplémentaire pour parvenir à une compréhension prétendument plus complexe de la variation d’un ensemble de données. L’efficacité de ces outils sera réexaminée dans Limitations de l’ABC XYZ.
Comment l’analyse ABC XYZ informe la politique de stocks
Les applications classiques de l’analyse ABC XYZ, tout comme l’analyse ABC, se concentrent sur l’attribution de niveaux de service et d’objectifs de stocks de sécurité. En utilisant la nouvelle matrice ABC XYZ, un praticien de la supply chain peut, en théorie, mieux visualiser les SKUs d’intérêt et ajuster les politiques de stocks pour refléter non seulement les préoccupations de chiffre d’affaires, mais aussi les forces de la variance de la demande.
Stocks de sécurité
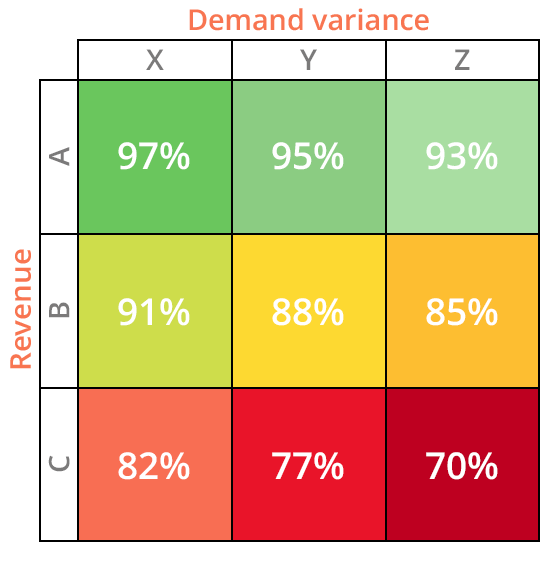
Une application immédiate de l’ABC XYZ est l’amélioration des objectifs de stocks de sécurité. Les SKUs de classe A reçoivent naturellement les niveaux les plus élevés, mais, contrairement à l’analyse ABC, il y a une tentative de différenciation entre les membres de la classe A (resp. C) en utilisant les classes XYZ le long de l’axe des x. C’est là que les partisans de l’analyse ABC XYZ soutiennent que cette approche brille le plus, et quatre extrêmes d’intérêt immédiat seront analysés ci-dessous à travers cette perspective.
- AX: Ces SKUs génèrent des revenus élevés et connaissent une faible variance. En tant que tel, un praticien de la supply chain pourrait décider que des niveaux de stocks de sécurité inférieurs sont nécessaires par rapport aux autres SKUs de classe A, afin d’atteindre des objectifs élevés de taux de service.
- AZ: Ces SKUs peuvent générer des revenus aussi élevés que ceux de AX et AY, mais connaissent une demande significativement plus variable. Par conséquent, des niveaux plus élevés de stocks de sécurité pourraient être jugés prudents.
- CX: Ces SKUs génèrent peu de profit et connaissent une faible variance. Des niveaux de stocks de sécurité faibles seraient probablement choisis (par rapport à AX, AY, AZ, BX, BY et BZ).
- CZ: Ces SKUs génèrent non seulement peu de profit, mais connaissent également des niveaux élevés de variance de la demande. Du point de vue de la supply chain, ces SKUs représentent le pire des deux mondes. Ces SKUs auraient théoriquement des niveaux de stocks de sécurité faibles et seraient des candidats privilégiés pour une éventuelle discontinuation.
En règle générale, l’analyse ABC XYZ indique que les SKUs nécessitent plus de stocks de sécurité à mesure que l’on avance le long de l’axe des x, en fonction de la difficulté accrue à prévoir la demande (les SKUs CZ étant une exception notable, comme décrit ci-dessus).
Taux de service
Intuitivement, maintenir des taux de service élevés sur les SKUs de classe A est d’une importance primordiale, bien que l’on puisse opter pour des niveaux inférieurs à mesure que l’on avance le long de l’axe des x. Par exemple, les SKUs AX auraient probablement un objectif de taux de service plus élevé que les SKUs AZ, compte tenu de la variance de la demande réduite associée aux premiers par rapport aux derniers. À mesure que l’on descend l’axe des y, les objectifs de taux de service sont généralement réduits, et, comme on pourrait s’y attendre, une politique sensée verrait les SKUs CZ recevoir les objectifs de taux de service les plus bas parmi les neuf catégories.
Figure 2. Une matrice ABC XYZ modèle avec revenu sur l'axe des y et variance de la demande sur l'axe des x. Cette matrice affiche les objectifs potentiels de taux de service pour chaque désignation, les niveaux diminuant à mesure que les revenus baissent et la variance de la demande augmente.
Limitations de l’ABC XYZ
Malgré le fait qu’elle offre (légèrement) une meilleure compréhension de son catalogue, l’analyse ABC XYZ est une tentative d’évolution qui conserve toutes les limitations de l’analyse ABC tout en apportant très peu de substance. En termes simples, c’est une innovation sans importance, et il n’est pas injuste de suggérer qu’elle invente même des classes de désavantages supplémentaires que l’analyse ABC ne possédait pas.
Objections pratiques à l’ABC XYZ
- Faible résolution : Tout comme l’analyse ABC, les neuf catégories d’une matrice ABC XYZ ne tiennent pas compte des tendances de la demande telles que les tendances à la hausse ou à la baisse (voir les t-shirts Harry Potter et Tesla dans la Figure 3), les offres limitées (voir le t-shirt Canal de Suez) et la saisonnalité (voir les chaussures d’hiver). Par conséquent, l’impact de ces éléments sur les politiques d’inventaire n’est pas du tout pris en compte. Cette limitation suppose également que le praticien de la supply chain n’a pas opté arbitrairement pour encore plus de classes le long de chaque axe, ce qui est tout à fait possible compte tenu de la nature laissez-faire de l’approche.
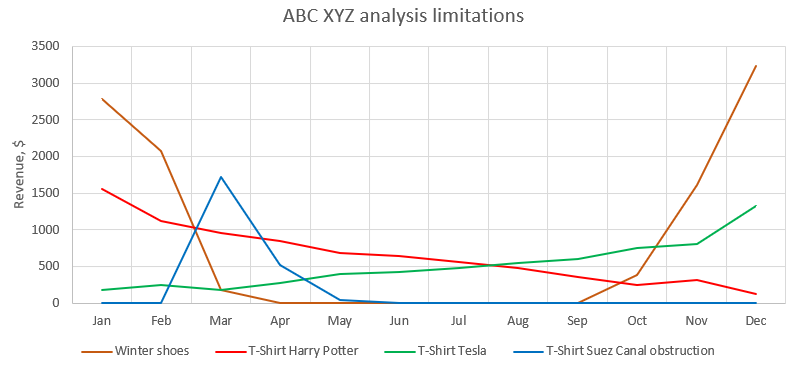
Figure 3. Le graphique en ligne montre les cas particuliers que l'analyse ABC XYZ a manqués dans l'ensemble de données du modèle. Par exemple, les t-shirts Harry Potter et Tesla ont tous deux fini en tant que SKU de classe BY et recevraient le même niveau de service et les mêmes objectifs de stock de sécurité. Cela ignore le fait que les SKU sont manifestement en train de tendre dans des directions complètement opposées.
-
Augmente l’instabilité : L’analyse ABC XYZ étend la catégorisation arbitraire et instable créée par l’analyse ABC. La différence réelle en termes de dollars et de cents entre CZ et CY, ou BZ et même BY, peut être insignifiante, voire presque financièrement imperceptible. De plus, tout comme dans une analyse ABC, ces différences pratiquement imperceptibles peuvent varier en fonction des horizons temporels sélectionnés. Par exemple, un SKU peut osciller entre AZ et CZ simplement en élargissant ou en réduisant la période de temps sélectionnée (par exemple, des horizons mensuels, trimestriels ou annuels). Tout comme la sélection des neuf catégories décrites ci-dessus, il n’y a pas plus ou moins de sens à choisir une période de temps plus longue ou plus courte.2 Ainsi, fixer des objectifs de niveau de service et de stock de sécurité basés sur de tels inputs instables est profondément erroné.
-
Augmente la bureaucratie : Par définition, les catégories instables décrites ci-dessus nécessitent une intervention de la direction pour établir des politiques distinctes pour chacune d’entre elles. Cela entraîne malheureusement une bureaucratie accrue et un gaspillage de ressources. Tout comme la différence entre un SKU de classe A et B peut être d’un seul point de pourcentage (ou de quelques dollars à peine), la différence de CV entre les SKU de classe Y et Z peut être faible au mieux. Ces paramètres sont totalement arbitraires et finalement déterminés par un comité, d’où leur provenance douteuse. Sachant que les SKU peuvent facilement passer entre les neuf catégories tout au long de la période observée (indépendamment de l’endroit où ils peuvent la terminer), fixer des niveaux de service arbitraires basés sur ces informations crée non seulement une administration et des réunions inutiles, mais augmente également la probabilité d’événements coûteux de rupture de stock. De plus, bon nombre, voire la plupart, des responsables impliqués dans la définition de ces paramètres arbitraires manqueront de la formation mathématique nécessaire pour comprendre l’approche, sans parler de pouvoir contribuer de manière significative aux recettes numériques. Cette critique est développée dans Les objections théoriques à ABC XYZ. Il convient également de souligner que, malgré la catégorisation et la bureaucratie accrues, l’analyse ABC XYZ n’identifie pas réellement pourquoi certains produits sont difficiles à prévoir, comme les SKU CZ. Elle détermine simplement qu’ils sont difficiles à prévoir, et la direction est laissée à se disputer sur les formules de stock de sécurité à appliquer arbitrairement à ces catégorisations aléatoires.
-
Manque de perspective financière : À sa base, l’analyse ABC XYZ repose sur une approche du premier ordre des moteurs économiques. En bref, cette mentalité considère les SKU uniquement en termes de leurs contributions marginales directes. Bien que l’analyse ABC XYZ semble également prendre en compte la variance de la demande, elle est toujours basée sur la contribution individuelle de chaque SKU dans un sens direct (par exemple, le chiffre d’affaires). Cette approche considère les SKU de manière isolée plutôt qu’en combinaison. Cette nuance est la marque d’une approche du second ordre, où la valeur d’un SKU CX, par exemple, est considérée par rapport à un SKU AX. Bien que le premier ne contribue peut-être pas de manière significative au chiffre d’affaires, l’avoir en stock peut faciliter la vente du second, de sorte que la valeur indirecte du CX peut largement dépasser sa valeur directe. Par conséquent, un processus de catégorisation déjà arbitraire, qui aboutit à des politiques de stock tout aussi arbitraires, est totalement aveugle à ces subtils moteurs économiques. Cela entraînera presque certainement des ruptures de stock pour des SKU dont la véritable valeur n’a pas été réalisée.3
Objections théoriques à ABC XYZ
À première vue, l’analyse ABC XYZ peut sembler être une version supérieure de l’approche ABC classique, les gens étant peut-être influencés par l’application apparente de principes mathématiques semi-avancés. Cependant, cette impression est injustifiée, car l’adoption par ABC XYZ de la théorie des moments est naïve, étant donné que l’analyse statistique implicite qu’elle cherche à effectuer est incomplète. Bien qu’il soit juste de dire que la moyenne et la variance font partie intégrante d’une analyse mathématique de ce type (c’est-à-dire comprendre la distribution d’une variable de demande aléatoire), il existe d’autres moments tout aussi instructifs qui sont complètement négligés.
Le troisième moment, l’asymétrie, n’est pas pris en compte dans une analyse ABC XYZ, pas plus que le quatrième moment, l’aplatissement. La façon dont les ventes sont réparties autour de la moyenne est mesurée par l’asymétrie.4 L’aplatissement, quant à lui, mesure à quel point la distribution est “pointue” ou “plate” par rapport à un ensemble de données normalement distribuées. Ces deux moments fournissent des informations valides sur les données sous-jacentes, c’est précisément pourquoi une analyse statistique robuste les inclurait en pratique courante.5
Par conséquent, la validité de l’investigation statistique dans une analyse ABC XYZ est au mieux incomplète et au pire trompeuse. En fait, la nature de l’informatique moderne et des techniques statistiques est telle qu’il n’est pas nécessaire de limiter son champ d’application à seulement quatre moments, donc même une future itération théorique d’ABC XYZ qui intègre ces moments serait toujours moins puissante en comparaison.
L’avis de Lokad
L’analyse ABC XYZ est, en fin de compte, une tentative inutile et malavisée d’améliorer l’analyse ABC. En mettant de côté les limites inhérentes de la classification ABC, les calculs XYZ ne permettent pas d’obtenir des informations significatives étant donné la méconnaissance de sa question de recherche et l’inadéquation de ses outils choisis pour l’exécuter.
L’objectif de l’analyse ABC XYZ est d’aider les praticiens à identifier des politiques d’inventaire appropriées pour les SKU difficiles à prévoir (par exemple, AZ ou CZ) sans identifier les raisons pour lesquelles ces SKU pourraient être difficiles à prévoir. De plus, elle ne fournit aucune perspective détaillée sur la manière dont les SKU interagissent (leur valeur indirecte), ce qui joue un rôle crucial dans la détermination des niveaux de service nuancés et des objectifs de niveau de stock respectifs. En ignorant ces préoccupations, l’analyse tâtonne essentiellement dans l’obscurité.
En ce qui concerne les outils sous-jacents, cette approche double les paramètres arbitraires de son prédécesseur et triple le nombre de classes, tout en incorporant une compréhension partiellement littéraire des statistiques. Cette transgression ne peut être ignorée, aussi bien intentionnés que puissent être les partisans d’ABC XYZ. Le danger potentiel réside dans l’apparence de rigueur que les calculs XYZ présentent aux lecteurs. Contrairement à l’analyse ABC, qui est accessible à presque tous ceux qui disposent d’un ordinateur fonctionnel et d’un cerveau en état de marche, ABC XYZ prétend exploiter quelques principes statistiques qui, pour les non-initiés, peuvent sembler assez avancés et impressionnants. Cependant, il s’agit d’une béquille de mots à laquelle on ne peut pas se fier. Une analyse statistique appropriée des données de vente est possible en utilisant des moments, mais cela nécessite une compréhension beaucoup plus approfondie des moments que celle que l’on trouve dans l’analyse ABC XYZ.
En fin de compte, l’analyse ABC XYZ sacrifie la robustesse statistique pour rester accessible au praticien général de la supply chain. Ce compromis aboutit à un processus qui amplifie l’instabilité et détourne les utilisateurs des problèmes sous-jacents d’intérêt. Les praticiens dont les entreprises ont dépassé de telles pratiques sont invités à envoyer un e-mail à contact@lokad.com pour organiser une démonstration d’une solution de production PIR - la réponse de Lokad aux problèmes que ABC XYZ tente de résoudre.
Notes
-
Généralement, les SKU de classe A, B et C, où A représente les plus rentables, C les moins rentables, et B quelque part entre les deux. La période de temps est généralement une année civile, mais cela peut varier. ↩︎
-
Certes, il y a une limite inférieure à l’utilité ; sélectionner une semaine de données n’aurait presque aucune valeur probante. Cependant, une fois qu’on a déterminé un ensemble de données historiques suffisamment profond (par exemple, 3 mois de ventes), il n’y a presque aucune objection logique à suggérer qu’il pourrait être augmenté d’un mois supplémentaire. Le résultat de cela, comme mentionné ci-dessus, déplacerait certainement les positions de certains SKU dans la matrice ABC XYZ. Cela souligne un autre problème du processus ABC XYZ : une fois qu’on a atteint une masse probante de données, le processus est immédiatement vulnérable à des ajustements supplémentaires. Cela s’oppose à ce que devrait faire une catégorisation : fournir des limites robustes et significatives entre les entrées. ↩︎
-
Il s’agit d’un résumé très bref de la perspective de Lokad et annonce la couverture des ruptures de stock en tant que moteur économique crucial. Ces concepts sont développés dans notre tutoriel sur le réapprovisionnement priorisé des stocks. ↩︎
-
Ou “SKU-ness” si vous préférez. ↩︎
-
Tout comme pi contient un nombre infini de chiffres, une fonction de densité de probabilité a un nombre infini de moments d’ordres différents. Cependant, en pratique, seuls les quatre premiers sont généralement utilisés. ↩︎