Reabastecimiento de inventario priorizado en Excel con pronósticos probabilísticos
La incertidumbre es un aspecto irreducible de los pronósticos. Sin embargo, en el siglo XX, los pronósticos estadísticos surgieron con la esperanza de que, dado modelos matemáticos adecuados, la incertidumbre pudiera ser eliminada. Como resultado, las teorías tempranas de la cadena de suministro minimizaron o descartaron la incertidumbre, ya que se esperaba que las técnicas de pronóstico más nuevas o mejores la eliminaran o, en caso de no lograrlo, la hicieran inconsecuente. Aunque bien intencionados, estos enfoques eran defectuosos ya que la incertidumbre, después de un siglo de modelado estadístico, sigue siendo irreducible. En 2012, Lokad pionero una perspectiva alternativa de cadena de suministro, una que abraza y cuantifica la incertidumbre. Este enfoque utiliza pronósticos probabilísticos en lugar de los clásicos pronósticos de series de tiempo. En esta guía, y la hoja de cálculo de Microsoft Excel que la acompaña, aplicamos pronósticos probabilísticos al problema de reabastecimiento de inventario. Este enfoque resulta en una política de reabastecimiento de inventario priorizada, demostrada aquí a través de Excel. Nuestro objetivo es doble: primero, popularizar este enfoque a una audiencia que puede no estar familiarizada con herramientas de software más avanzadas; y segundo, demostrar que abrazar la incertidumbre requiere una mentalidad determinada más que herramientas sofisticadas.
Descargar: probabilistic-inventory-replenishment.xlsx
1. El problema de reabastecimiento de inventario
El problema de reabastecimiento de inventario se centra en identificar la mejor lista de compras, una que tenga en cuenta las restricciones financieras y los objetivos principales de la empresa. El método para producir dicha lista debe funcionar igual de bien independientemente de las restricciones presupuestarias, dado que el método intenta maximizar el retorno de la inversión por cada dólar gastado. El problema es que todos los SKU compiten por los mismos dólares, por lo que el retorno financiero de almacenar cualquier unidad de un SKU determinado debe ser cuantificado y clasificado en el contexto de todas las unidades adicionales de cada SKU.
1.1 La solución de reabastecimiento de inventario priorizada
El proceso de clasificación de inventario, como se describe anteriormente, requiere una perspectiva a nivel micro. Para comparar el retorno de agregar cualquier unidad de un SKU a una lista de compras, se deben considerar varios factores. Específicamente, la probabilidad de venta según lo proporcionado por un pronóstico de demanda probabilístico y los impulsores económicos, como el margen de ganancia bruta y el precio de compra. A su vez, cada cantidad considerada debe equilibrarse con respecto a las restricciones internas y externas (como la capacidad limitada de almacenamiento, los multiplicadores de lote y los MOQs/MOVs, etc.). Los casos extremos, como cuando dos (o más) unidades tienen igual rentabilidad esperada, deben tenerse en cuenta en una política de reabastecimiento de inventario a través de la evaluación de la importancia relativa de cada producto. Los SKU no deben considerarse de forma aislada, sino en conjuntos. Algunos SKU, a pesar de tener márgenes de ganancia más bajos de forma aislada (como la leche), son más importantes ya que facilitan las ventas de productos de alto margen. Por lo tanto, la recompensa financiera por mantener los niveles de servicio de un producto de margen más bajo, que facilita otras ventas, representa otro impulsor (“cobertura de faltante de stock”)1. Un enfoque de reabastecimiento de inventario priorizado (PIR), utilizando pronósticos probabilísticos como entrada, tiene en cuenta todos los factores descritos anteriormente.
En resumen, la solución PIR se puede resumir en tres pasos:
1. Construir un pronóstico de demanda probabilístico.
2. Enumerar todas las cantidades de compra factibles.
3. Clasificar todas las cantidades de compra factibles con impulsores económicos.
1.2 Reabastecimiento de inventario priorizado en Excel
Utilizando datos financieros de una tienda ficticia, incluidos los impulsores económicos mencionados en la sección anterior, esta hoja de cálculo de Excel modela la política de reabastecimiento de inventario para tres SKU (bolígrafos, teclados y estanterías)2. Las consecuencias financieras de cada unidad adicional de SKU (si se ordena) y la probabilidad de venderlo se ilustran en la hoja Gráficos (ver Figura 1). Los diagramas y gráficos se actualizarán según las entradas y las suposiciones del modelo (por ejemplo, niveles de stock iniciales, precios de compra y venta, etc.) en la hoja Torre de control (Figura 2). Se genera una lista detallada de opciones de decisión factibles en la hoja Decisiones de compra micro (Figura 3) en función de las entradas clave. Estas entradas son los pronósticos de demanda probabilísticos de la hoja Generadores de distribución (Figura 4) y las entradas de la hoja Torre de control. Por último, se recopila y clasifica una tabla de decisiones de reabastecimiento de inventario priorizadas en términos de retorno esperado de la inversión (ver hoja Decisiones de compra clasificadas en la Figura 5).
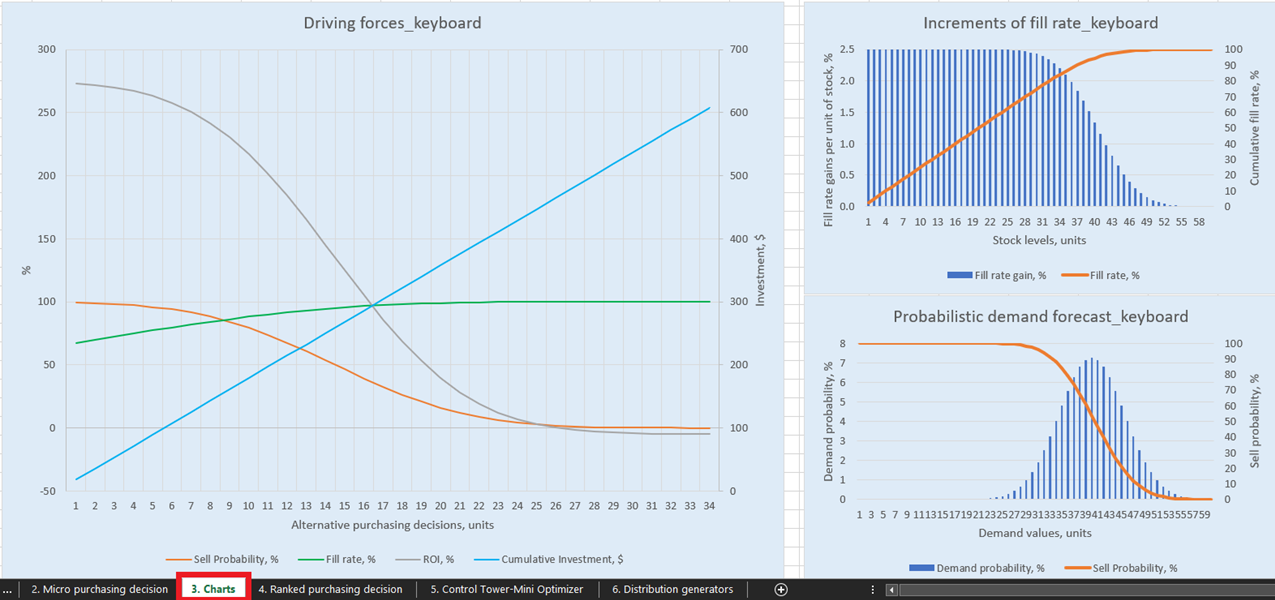
Figura 1. Vista del "teclado de fuerzas impulsoras" en Gráficos, ubicación resaltada en rojo.
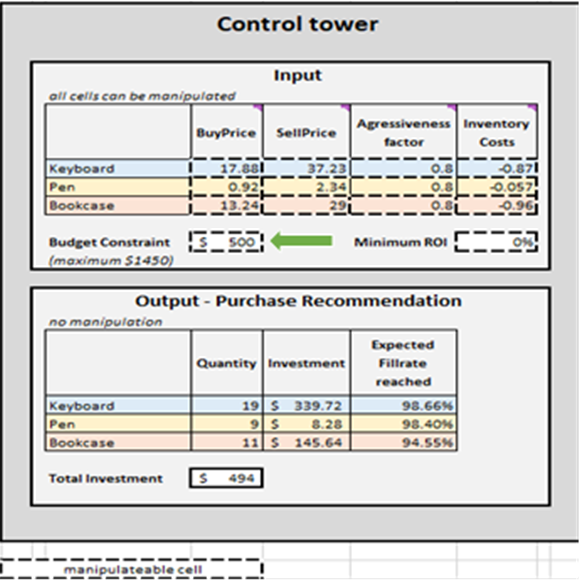
Figura 2. Vista de la "Torre de Control" ubicada en Torre de Control - Mini Optimizer (hoja 5). Se puede editar la "Restricción de Presupuesto" a cualquier valor entre $0 y $1450 (ver flecha verde).
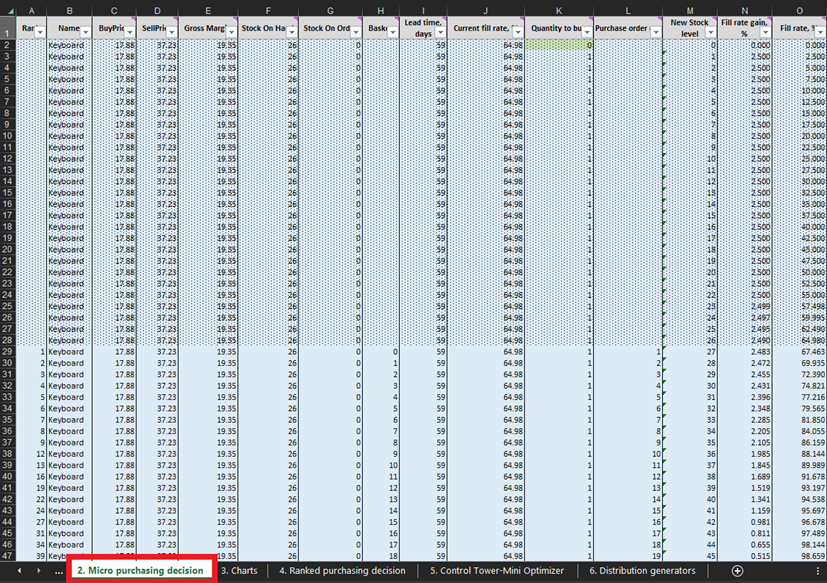
Figura 3. Dónde ubicar las decisiones de compra micro dentro de Excel, resaltadas en rojo. Las filas cubiertas por el formato condicional punteado son datos pasados (hasta e incluyendo la línea 28 en la imagen anterior). Esta información representa decisiones de compra anteriores. Solo nos preocupamos por todo lo que está debajo de este formato condicional. El mismo formato punteado se aplica a los datos de bolígrafo y estantería.
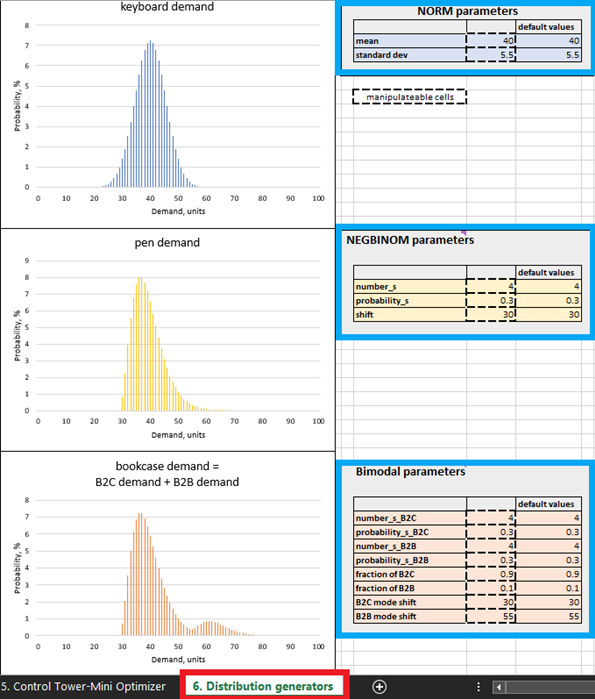
Figura 4. Dónde ubicar los generadores de distribución dentro de Excel, resaltados en rojo. Los paneles de control de productos están resaltados en azul. Las celdas con contornos punteados se pueden manipular.
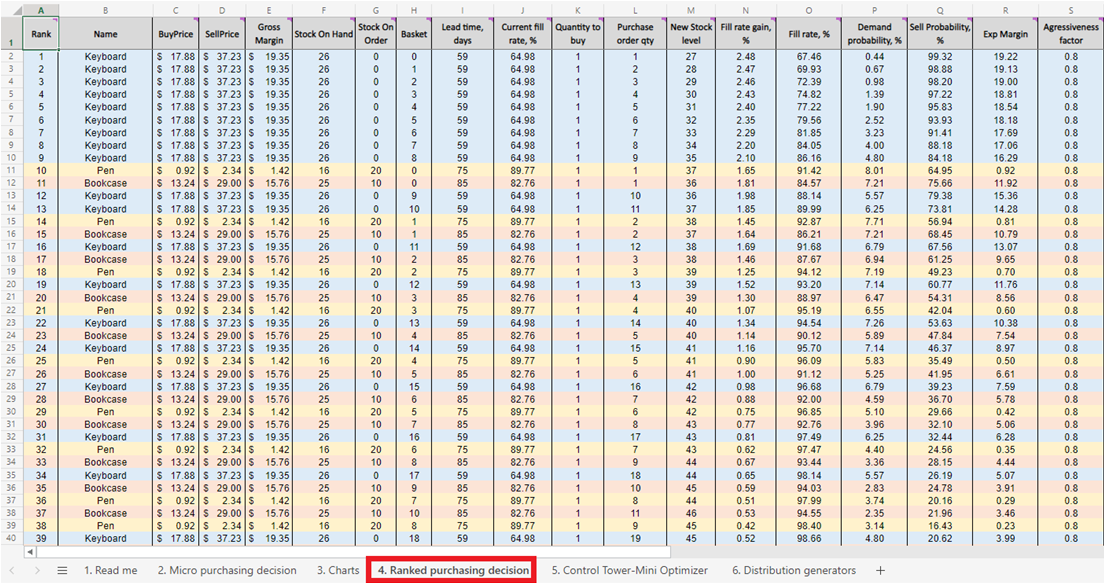
Figura 5. Una lista de reabastecimiento de inventario priorizada de decisiones de compra micro, ubicada en la hoja 4.
2. Pronóstico de Demanda Probabilístico
En este contexto, un pronóstico probabilístico es un conjunto de todos los valores de demanda futura probables y sus respectivas probabilidades. Abarca la incertidumbre inherente de la demanda futura y se puede construir en cualquier período de tiempo. Al igual que un pronóstico tradicional de series de tiempo, se identifica un único valor de demanda más probable (los puntos blancos en la Figura 6) y una línea de tendencia (la línea gris que conecta los puntos blancos). Sin embargo, un pronóstico probabilístico integra la incertidumbre a través de la adición de todos los posibles valores de demanda (aunque no igualmente probables). Este enfoque se puede observar en la Figura 6, donde diferentes intervalos de confianza representan valores de demanda con diferentes probabilidades.
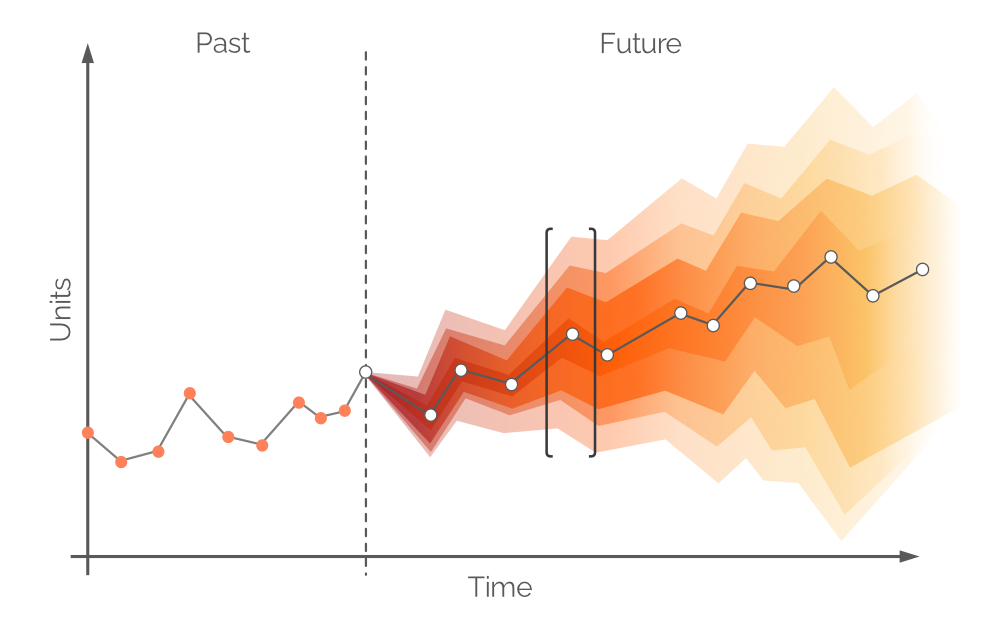
Figura 6. Un pronóstico probabilístico (demanda en el eje y; tiempo en el eje x). La línea vertical punteada en gris indica el momento actual ("ahora"). El tiempo se mide en días, aunque podría ser cualquier intervalo deseado. El área en corchetes negros se discutirá más adelante.
Los puntos blancos en la Figura 6 representan los valores de demanda más probables en intervalos futuros fijos. Hay una banda de color acompañante que corresponde a un rango de valores de demanda futuros alternativos, una distribución de probabilidad en color. Este color se desvanece a lo largo del eje vertical a medida que uno se aleja del punto blanco, lo que representa una mayor incertidumbre y una menor probabilidad. En general, las bandas de color se desvanecen a medida que avanza el tiempo (a lo largo del eje horizontal), ya que la incertidumbre se intensifica con el paso del tiempo. Sin embargo, independientemente de la incertidumbre, siempre hay al menos un valor que es el más probable, y esto se representa en todo momento mediante los puntos blancos. Un ejemplo de una distribución de probabilidad para un punto en el tiempo se ilustra en la Figura 7.
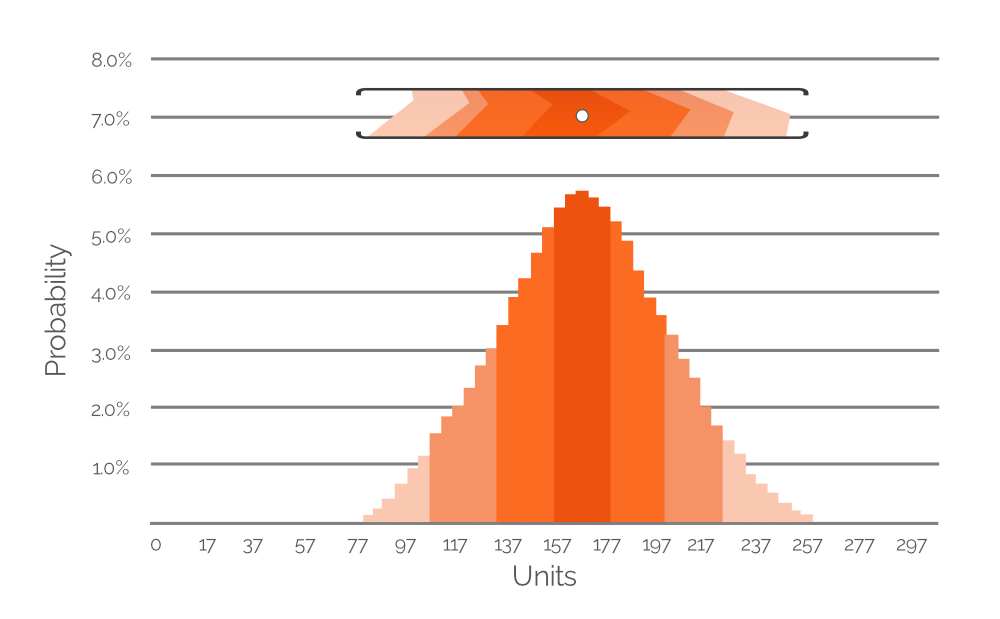
Figura 7. Un histograma que representa la probabilidad de varios valores de demanda posibles (en intervalos de 20 unidades). El eje y es el valor de probabilidad; el eje x es la demanda en unidades. El histograma es una representación del rango de valores destacado en la Figura 6 (incluido aquí con fines de referencia).
La Figura 7 expresa los datos destacados de la Figura 6 como un histograma de probabilidad, con valores numéricos explícitos que denotan la probabilidad de diferentes valores de demanda. La codificación de colores se mantiene para facilitar la comprensión (recuerde, los colores más tenues son menos probables; los colores más densos son más probables). En este ejemplo, el valor de demanda más probable es de 167 unidades (+/-), por eso el punto blanco en el rango de valores recortado de la Figura 6 se posiciona directamente sobre la barra más alta del histograma. Sin embargo, también asignamos probabilidades de demanda a valores de demanda extremadamente bajos y altos (alrededor de 80 y 260 unidades, respectivamente, ambos de color naranja muy tenue). Esto demuestra la riqueza potencial de datos de un pronóstico probabilístico y se incluyen histogramas similares en la hoja de cálculo de Excel, uno para cada uno de nuestros SKUs (ver Figura 4). Utilizando estos histogramas (como en la Figura 7 anterior), se pueden identificar los valores de demanda (en unidades) con probabilidades no nulas de ocurrencia y se pueden tener en cuenta en el PIR.
2.1 La construcción de un pronóstico probabilístico
Aunque es posible construir un pronóstico probabilístico real con datos históricos en Excel, es posiblemente la herramienta menos capaz para este propósito. En general, los detalles específicos de construir un pronóstico probabilístico de calidad de producción están más allá del alcance de este documento, por lo tanto, se seleccionaron pronósticos probabilísticos sintéticos por simplicidad. Los parámetros de estos pronósticos sintéticos se pueden manipular en Generadores de distribución (ver Figura 4). Sin embargo, se recomienda estudiar primero la configuración predeterminada antes de realizar ajustes.
En las prácticas de la cadena de suministro convencionales, la demanda se considera típicamente distribuida normalmente, sin embargo, esto es una rareza. En las cadenas de suministro del mundo real, la mayoría de los SKUs se desvían de los patrones de distribución normal. Dada esta realidad, seleccionamos deliberadamente tres patrones de distribución diferentes: normal (para teclados), binomial negativa (para bolígrafos) y bimodal (para estanterías - una mezcla de dos patrones binomiales negativos). Lo siguiente proporciona justificación para esta suposición.
Por ejemplo, asumimos que las estanterías son compradas tanto por individuos como por empresas (por ejemplo, escuelas), por lo tanto, utilizamos una distribución bimodal. En la configuración predeterminada de las estanterías, hay una demanda frecuente por parte de los individuos, con una o dos unidades compradas por cliente. Esto representa el primer modo de la distribución (ver Figura 4). Sin embargo, las empresas representan fuentes de demanda menos frecuentes pero realizan pedidos más grandes (más grandes de lo que suelen hacer los individuos). Cuando esto sucede, su demanda se suma a la demanda generada por las compras de los individuos, y aparece el segundo modo de la distribución. Este segundo modo se desplaza hacia la derecha (representando valores altos de demanda) y es notablemente más pequeño que el primer modo, lo que refleja el hecho de que ocurre con menos frecuencia (Figura 4). Nuestro modelo también asume que los bolígrafos son comprados por individuos con una demanda ocasionalmente alta (por ejemplo, estudiantes que compran antes de las fechas de exámenes escolares). Finalmente, para reflejar el hecho de que una distribución normal ocurre ocasionalmente, las ventas de teclados siguen un patrón de distribución normal.
Dentro de los Generadores de distribución (Figura 4), se pueden editar las distribuciones de demanda cambiando los parámetros en las celdas manipulables. Por ejemplo, aumentar la media para los teclados (ver “Parámetros NORM” en la Figura 4) de 40 a 50 hará que la distribución se desplace 10 unidades hacia la derecha. Como resultado de este aumento en la demanda media, el ROI esperado para todas las unidades de teclado aumentará. De manera similar, se pueden realizar modificaciones en los parámetros de las distribuciones binomial negativa (bolígrafos) y bimodal (estanterías).
Dado que Excel carece de la expresividad para este tipo de cálculos, esta demostración limita las modificaciones a 100 unidades por producto. Por ejemplo, establecer la media de los teclados en 99 hará que casi el 50% de las unidades de demanda no se calculen en la hoja de Decisiones de compra micro.
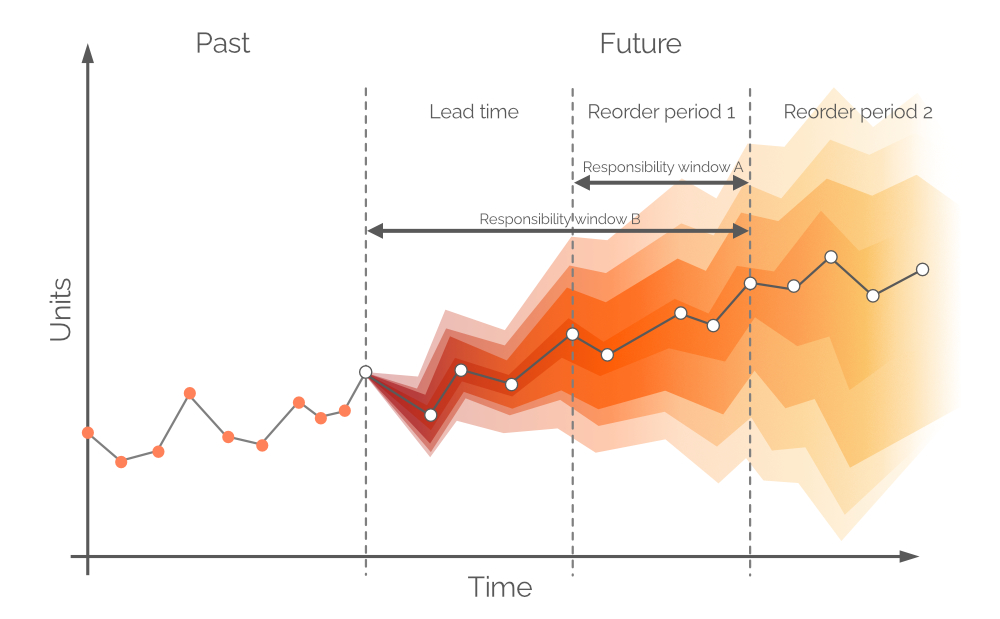
2.2 Selección de un horizonte para un pronóstico de demanda probabilístico
Típicamente, los pronósticos se dividen en intervalos diarios/semanales/mensuales, aunque estos períodos discretos tienen una utilidad y valor limitados desde una perspectiva de reabastecimiento. La demanda durante el próximo tiempo de entrega no puede ser cubierta por decisiones de compra realizadas hoy a menos que se permitan backorders, porque cualquier unidad comprada llegará después de un período igual al tiempo de entrega. Por lo tanto, la demanda debe ser cubierta con el stock en mano de la tienda y el stock en pedido (ver Figura 8), asumiendo que las unidades en pedido lleguen antes de la demanda. Por lo tanto, el pronóstico probabilístico se refiere a la demanda entre los puntos de reorden o, en otras palabras, la demanda durante el Período de reorden 1 (ver Figura 9). La demanda futura más distante se cubrirá con pedidos futuros (ver Período de reorden 2, en la Figura 9).

Figura 8. Stock en mano (columna F) y Stock en pedido (columna G), resaltados en rojo, se encuentran en Decisiones de compra micro. El tiempo de entrega, columna I, se resalta en azul.
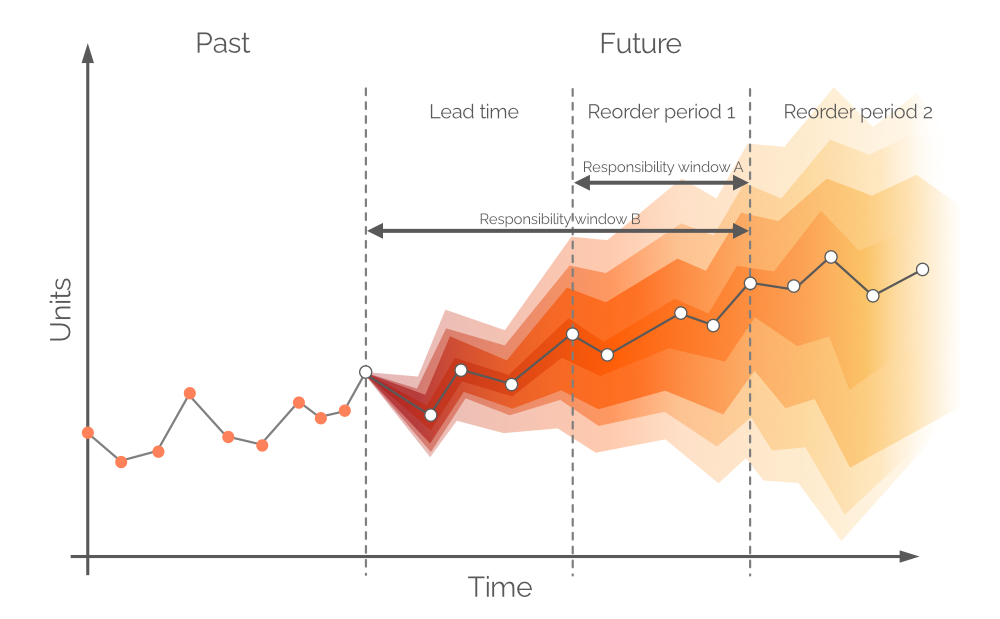
Figura 9. Una representación visual de las ventanas de responsabilidad alternativas. La demanda se encuentra en el eje y, el tiempo en el eje x, con la línea vertical gris punteada a la izquierda que indica el momento actual ("ahora", según la Figura 6). El pronóstico probabilístico en este documento se refiere a la demanda durante el horizonte igual a Ventana de responsabilidad B.
En teoría, el pronóstico de demanda probabilístico debería construirse durante el período de tiempo igual a Período de reorden 1 - esta ventana de tiempo se denomina Ventana de responsabilidad A (ver Figura 9). Para hacer esto, necesitaríamos hacer proyecciones futuras para el stock en mano y el stock en pedido al final del tiempo de entrega. Sin embargo, la demanda durante el tiempo de entrega - para la cual ya tomamos decisiones durante el período de pedido anterior - también es probabilística, y esto resultaría en niveles de stock que son distribuciones de probabilidad en sí mismas3. Al permitir pedidos atrasados (una práctica común en algunos sectores), se puede construir un pronóstico probabilístico durante un período conjunto (tiempo de entrega más período de reorden 1, según la Figura 9, también conocida como Ventana de responsabilidad B).
Se puede suponer que los niveles actuales de stock en mano y stock en pedido satisfarán la demanda durante el período de tiempo de entrega. Si hay un evento de faltante de stock, cualquier demanda posterior se cubrirá con pedidos atrasados. Estos pedidos atrasados serán atendidos por las decisiones de compra micro tomadas a partir de hoy. Esto nos permite tratar el stock en mano y el stock en pedido como valores discretos (en lugar de aleatorios)4.
3. Identificación de opciones de decisión de reabastecimiento factibles
En un escenario real de reabastecimiento de inventario, se deben delinear todas las opciones de decisión factibles, porque no hay una forma directa de pasar de un pronóstico probabilístico a la mejor decisión única (cantidad de compra, en este caso) para cada producto. En lugar de una única elección “perfecta”, un enfoque probabilístico presenta una variedad de decisiones posibles que se deben considerar en términos de factibilidad.
Factibilidad aquí tiene el significado pedestre de que una decisión es inmediatamente ejecutable; se puede ejecutar “tal cual” sin más cálculos o verificaciones. Por ejemplo, una decisión es “factible” si es rentable y satisface todas nuestras restricciones (por ejemplo, MOQs, EOQs, tamaños de lote, envíos completos de contenedores, y cualquier otra restricción que pueda existir en nuestra cadena de suministro)5.
En cada línea de la hoja de Decisiones de compra micro (Figuras 3 y 10), debemos considerar agregar una unidad más de stock a nuestro pedido de compra para un producto en particular6. Nuestro “presente” (o Día 1 de este experimento) comienza en la línea 29, que muestra el nivel de stock actual. Esto se calcula como la suma de Stock en mano y Stock en pedido. Si decidimos agregar una unidad al pedido de compra, la cantidad total de compra se calculará en la Columna L como la suma de todas las unidades consideradas hasta ahora para la compra (ver notas en la Figura 10).
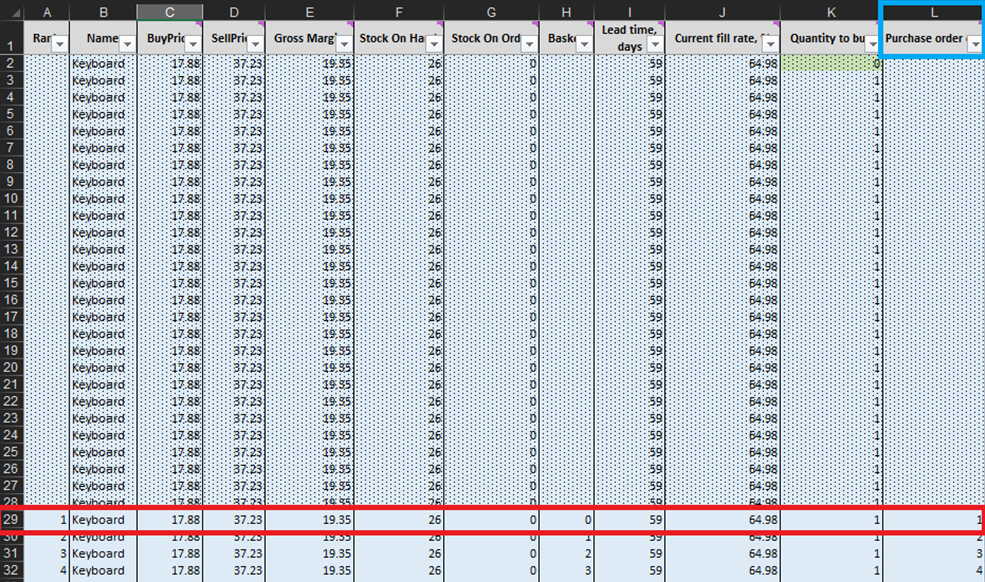
Figura 10. Vista desde la hoja de Decisiones de compra micro. La línea 29, resaltada en rojo, es donde comienza nuestro experimento (para teclados). La columna de pedido de compra está resaltada en azul. El mismo principio se aplica a las líneas 140 (para pedidos de bolígrafos) y 240 (para pedidos de estanterías).
Una vez que se hayan identificado estas decisiones de inventario factibles, calcularemos y clasificaremos la recompensa económica de cada posible compra. Tenga en cuenta que no evaluamos la recompensa de compra para las unidades que actualmente están en stock en mano o stock en pedido (columnas F y G en la Figura 10). Dado que ya compramos estas unidades, la recompensa económica teórica se determinó (y clasificó) en una fecha anterior. Por ejemplo, si observamos los datos de los teclados en la Figura 10, actualmente hay 26 unidades en stock. Por lo tanto, comenzaremos los cálculos en la línea 29 y consideraremos si debemos pedir nuestra primera unidad de stock adicional (lo que elevaría los niveles de stock de 26 a 27 unidades).
3.1 Evaluación de decisiones de compra factibles
Para elegir la mejor cantidad de compra para cada producto, es necesario calcular el retorno monetario esperado a nivel de unidad para cada cantidad factible para cada producto (considerando el futuro incierto representado por el pronóstico probabilístico). Este es un concepto de valor esperado adaptado al nivel más granular de inventario toma de decisiones.
En realidad, se deben considerar todo tipo de impulsores económicos al intentar calcular el retorno esperado para cada decisión factible7. Para los fines de esta demostración, aquí están los factores que consideraremos:
- Precio de venta: Cuánto cobramos a los clientes por el producto.
- Costo de almacenamiento: Cuánto nos cuesta mantener el producto.
- Precio de compra: Cuánto nos cuesta comprar el producto a nuestro proveedor/mayorista.
- Cobertura de faltante de stock: Se explica en detalle a continuación, ya que es un impulsor menos conocido pero igualmente importante8.
Figura 11. Nota explicativa para el Precio de compra, visible al pasar el cursor sobre el encabezado de la columna. Hay una definición para cada columna en cada hoja del documento de Excel.
La cobertura de faltante de stock representa un incentivo financiero para mantener una unidad de un producto en stock, pero no con el objetivo explícito de venderlo. Este impulsor económico se utiliza para modelar la importancia relativa de un producto en comparación con otros. Incentiva evitar un evento de faltante de stock para productos que podrían considerarse menos importantes debido a sus contribuciones de margen directas, ya que estos productos pueden contribuir significativamente a los márgenes de beneficio de manera indirecta. Como tal, se asemeja más a un impulsor de recompensa9. Aunque este impulsor es difuso, es crucial identificar todos los productos críticos (incluso aquellos que no son impulsores de margen directos).
3.2 Cálculo de la puntuación de cada decisión factible
La consecuencia económica total (o recompensa de compra) de una decisión de reabastecimiento de inventario es la suma de todos los impulsores económicos, incluyendo margen esperado, costo esperado de inventario, y cobertura de faltante de stock (definidos en detalle a continuación). El costo de almacenamiento se incluye en estos cálculos como un impulsor negativo, actuando como una fuerza contraria para equilibrar nuestras decisiones de reabastecimiento de inventario.
A continuación se muestra un análisis de las implicaciones económicas de las fórmulas en cada columna, utilizando la línea 29 de la hoja Decisiones de compra micro como ejemplo (ver Figura 12).

Figura 12. Desglose de los impulsores por columnas clave, utilizando la línea 29 de Decisiones de compra micro (hoja de Excel 2). Se ocultaron ciertas columnas para mayor comodidad en la figura.
Para calcular la recompensa esperada para cada decisión, necesitamos los siguientes impulsores:
Margen bruto (columna E) = Precio de venta - Precio de compra.
Probabilidad de venta (columna Q) = verificar fórmula en la hoja10.
Probabilidad de no venta (sin columna) = 100% - Probabilidad de venta
Margen esperado (columna R) = Margen bruto * Probabilidad de venta/100.
Factor de agresividad (columna S) = Varía de 0 a 1. Se seleccionó 0.8 para esta herramienta.
Cobertura de faltante de stock (columna T) = Precio de venta * Factor de agresividad * Probabilidad de venta
Costo de almacenamiento (columna U)
Costo esperado de inventario (columna V) = Costo de almacenamiento * Probabilidad de no venta11.
Utilizando los datos anteriores, la recompensa de compra para cada decisión de inventario a nivel micro (cada unidad de cada producto) se calcula de la siguiente manera:
Recompensa de compra (columna W) = Margen esperado + Cobertura de faltante de stock + Costo esperado de inventario.
Una vez que tenemos la estimación de la recompensa de compra, podemos calcular la puntuación final que luego utilizaremos para clasificar todas las decisiones consideradas.
Puntuación (columna Y) = Recompensa de compra / Inversión (columna X)12.
Dado que la cobertura de faltante de stock es un impulsor difuso que incorpora tanto los retornos directos como indirectos, la recompensa de compra no es un reflejo estricto del retorno esperado de una decisión de inventario en aislamiento. Si se desea calcular este tipo de retorno, se debe excluir la cobertura de faltante de stock de esta fórmula13.
4. Clasificación de las Decisiones de Reposición de Inventario Factibles
Una vez que tenemos la puntuación para cada decisión de compra de inventario factible (para cada producto), se genera una lista y se ordena en orden descendente (de mayor a menor) en Decisiones de compra clasificadas (ver Figura 13). Cada decisión de inventario factible se ordena en términos de porcentaje de ROI positivo. También se asigna un rango ordinal (1º, 2º, 3º, etc.) a cada decisión (ver columna A en la misma figura).
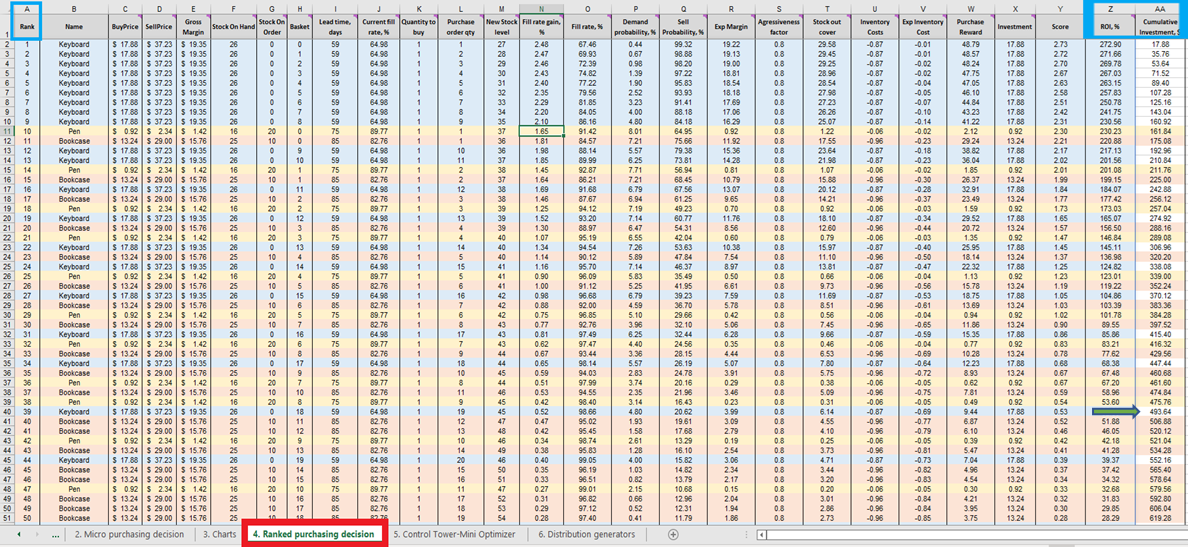
Figura 13. Ubicación de las decisiones de compra clasificadas resaltada en rojo. Las columnas A, Z y AA están resaltadas en azul. La celda 40 (el punto de corte para un presupuesto de $500 - el valor predeterminado de la hoja de cálculo) está indicada por la flecha verde.
Decisiones de compra clasificadas presenta filas codificadas por colores para cada producto (teclados, bolígrafos y estanterías), utilizadas aquí para demostrar cómo la elección de agregar una sola unidad adicional de cualquier producto dado interactúa con cada otra unidad adicional de cada otro producto. Cada una de estas decisiones de inventario influye colectivamente en el ROI. Finalmente, se calcula un valor de inversión acumulativa (columna AA, Figura 13). Esto se puede utilizar para indicar dónde se debe terminar las decisiones de compra en función de las restricciones presupuestarias, aunque este es solo un posible indicador de terminación14.
5. Determinación de los Criterios de Terminación
En términos de seleccionar un punto de terminación (tanto en Decisiones de compra clasificadas como en la realidad), los criterios variarán dependiendo de una serie de variables. Por ejemplo, uno podría tener un presupuesto modesto y, por lo tanto, maximizar el ROI es problemático dado los márgenes especialmente ajustados. Alternativamente, es posible que uno tenga un objetivo general para el nivel de servicio y luego deba equilibrar esta prioridad con el impulso de maximizar los márgenes de beneficio.
Para ser aún más detallado, los criterios de terminación podrían abarcar un impulso para maximizar el ROI con objetivos de nivel de servicio variables para cada producto o categoría. Los criterios de terminación son, por lo tanto, una elección estratégica que debe hacerse después de una reflexión franca sobre los objetivos comerciales generales de una empresa. La reposición de inventario priorizada (PIR) es notablemente flexible en este sentido; los criterios de terminación para cada ciclo de compra se pueden ajustar utilizando el mismo procedimiento de clasificación general.
Para visualizaciones explícitas de nuestras posibles decisiones de reposición de inventario, hay tres gráficos para cada producto en el panel de control dashboard (hoja 3, ver Figura 14). De particular interés es “Fuerzas impulsoras_nombre del producto” (se utiliza el ejemplo de Teclado en la Figura 14), que muestra la evolución del ROI dado diferentes cantidades de compra a nivel de unidad.
Como se puede ver en el gráfico, hay un punto en el que aumentar las cantidades de compra resultará en un ROI negativo. Esto se debe a que, en cierto nivel, no tiene sentido comprar más unidades, ya que nuestros márgenes esperados se reducirán críticamente debido a los aumentos en los costos esperados de inventario.
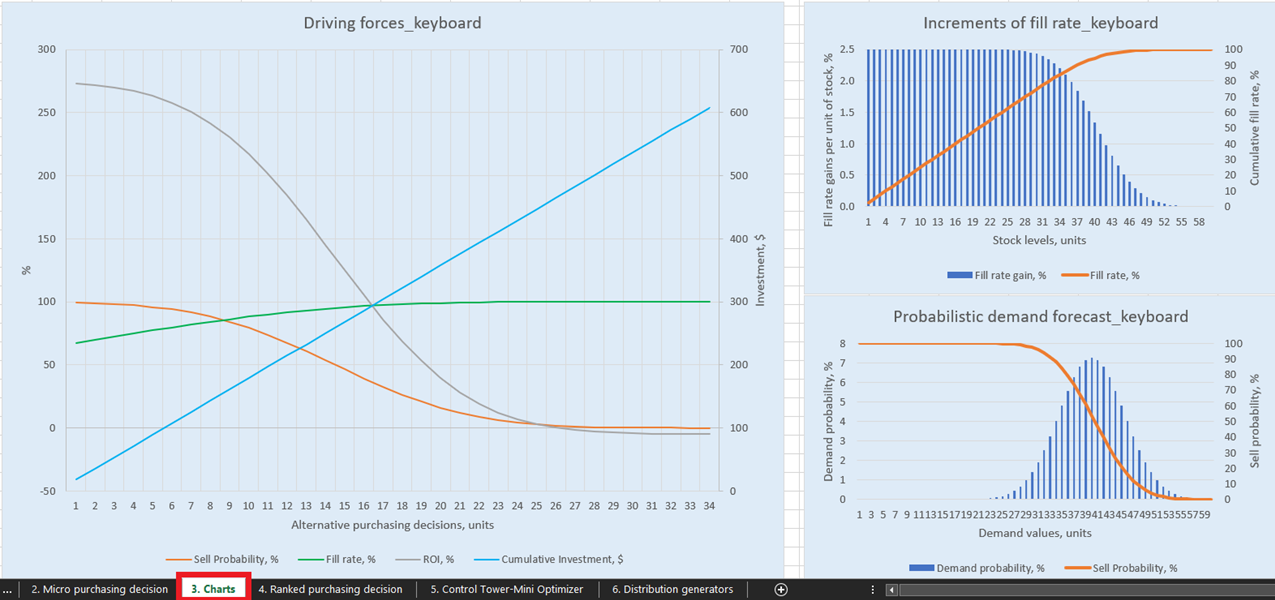
Figura 14. Vista de "Fuerzas impulsoras_teclado" en Gráficos, ubicación resaltada en rojo.
Una vez que se determinan los criterios de terminación, las decisiones de reposición de inventario priorizadas se agregan por SKU, lo que a su vez actualiza la Cantidad, Inversión y Tasa de llenado esperada alcanzada en la Recomendación de compra de salida para cada SKU (ver Figura 15). Se pueden modificar las restricciones presupuestarias ($0 a $1450), lo que, a su vez, actualizará la lista de compra recomendada. Por conveniencia, el panel de control cuenta con dos bloques adicionales: Caso base - copia impresa y Cambios en el escenario base. El primero es estático y muestra la configuración predeterminada para la demostración según lo diseñado por Lokad; el último muestra la diferencia entre las modificaciones realizadas y la configuración predeterminada de Lokad.
La lista de recomendación de compra en la torre de control representa el objetivo de esta demostración (ver Figura 15).
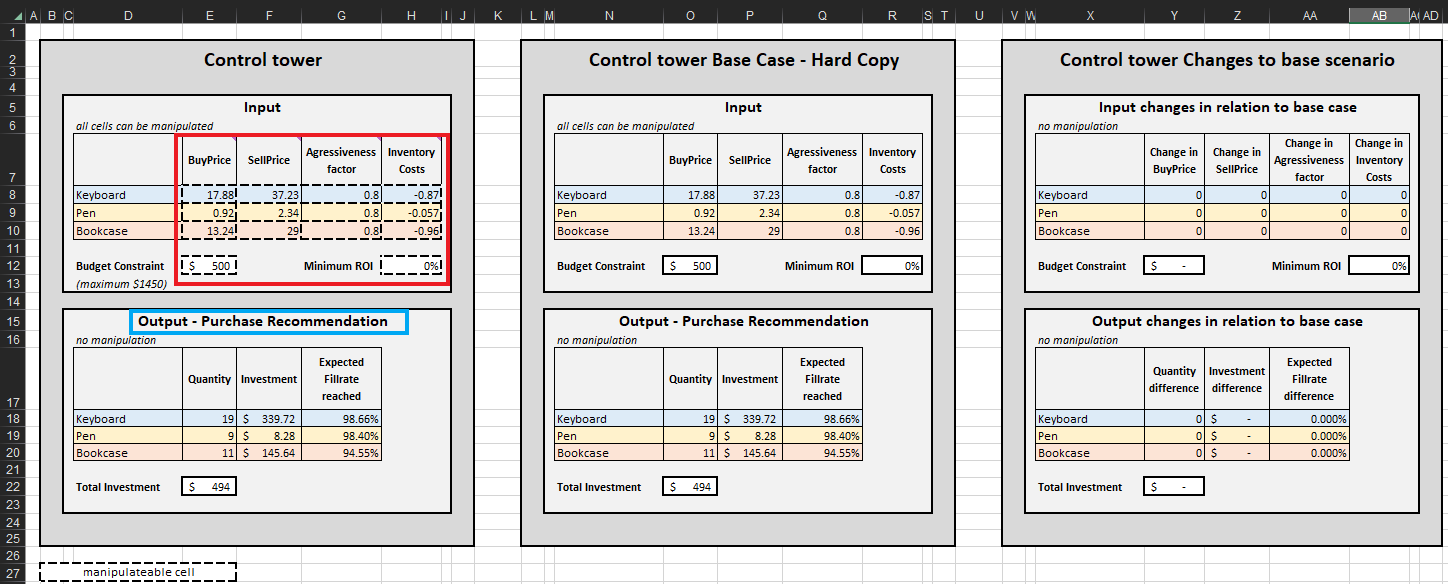
Figura 15. Vista de Torre de Control-Mini Optimizer (hoja 5). Las celdas manipulables se resaltan en rojo. "Recomendación de compra" se resalta en azul y representa el objetivo de un enfoque de reposición de inventario priorizado.
6. Conclusión
Las previsiones tradicionales de series temporales son simplemente incapaces de capturar el nivel de detalle necesario para tomar decisiones de reposición de inventario que reflejen la incertidumbre futura y la escala completa de las restricciones y los impulsores. Esto se debe a que carecen de una dimensión explícita de incertidumbre, representada por valores de probabilidad para los resultados futuros esperados. Como una serie temporal tradicional es efectivamente ciega a este tipo de datos, un método clásico de afrontamiento como el stock de seguridad se reduce a conjeturas; si se tiene poco, se pierden ventas rentables con un ROI esperado positivo; si se tiene demasiado, se reduce el ROI al almacenar unidades que (como se demuestra en la hoja de cálculo) tienen un ROI esperado negativo.
La reposición de inventario priorizada, utilizando previsiones probabilísticas, es nuestra solución a este problema. Este enfoque considera las opciones de reposición de inventario en combinación, en lugar de de forma aislada. Al hacerlo, se puede cuantificar y revelar plenamente la recompensa financiera esperada de nuestras opciones de reposición de inventario. La base de este enfoque es abrazar la incertidumbre y aprovechar las entradas de pronóstico probabilísticas. A su vez, también se puede obtener una mayor comprensión de qué niveles de servicio (por SKU) generan recompensas financieras significativas, en lugar de establecer objetivos arbitrarios.
El enfoque PIR demostrado en este documento se construyó utilizando datos sintéticos y parámetros estrechos. Estas elecciones se hicieron para adaptar una herramienta común (Excel) a un propósito poco común (PIR). Entre otras concesiones necesarias, se limitaron los SKU y las unidades (a 3 y 100, respectivamente) para reducir el tiempo de procesamiento, ya que sería demasiado laborioso procesar todos los datos de un catálogo completo (y mucho menos los datos de varias tiendas). Además, no se agregaron restricciones de cadenas de suministro. Es crucial destacar que Excel no está diseñado para procesar variables aleatorias, un paso clave para generar pronósticos probabilísticos y políticas de PIR. Estas limitaciones no se aplican a una solución de PIR de calidad de producción.
Los profesionales de la cadena de suministro cuyas empresas han superado Excel pueden enviar un correo electrónico a contact@lokad.com para concertar una demostración de una solución de PIR de calidad de producción.
7. Descripción general de la hoja de cálculo
7.1 Leerme
Esta hoja sirve como página de inicio para el usuario. Hay un enlace a un tutorial en línea (el que está leyendo ahora).
7.2 Decisiones de compra micro
Esta es la segunda hoja y está dedicada al análisis financiero de granularidad fina de todas las opciones factibles de decisión de reposición. Tenga en cuenta que aquí no se realiza ninguna manipulación manual de datos. Esta hoja solo muestra los resultados de los cálculos basados en las entradas de las hojas Torre de Control y Generadores de Distribución.
Características clave:
- Las filas con formato condicional son “decisiones pasadas” y no se pueden modificar. Recomendamos utilizar una aplicación de escritorio, ya que la versión basada en navegador de Excel a veces no es confiable en cuanto al formato.
- Al pasar el cursor sobre cada encabezado de columna se revelará una definición/nota útil.
7.3 Gráficos
Esta es la tercera hoja y está dedicada a visualizar los principales impulsores en juego en las decisiones de reposición de inventario. Tenga en cuenta que aquí no se realiza ninguna manipulación manual de datos. Esta hoja está diseñada para ayudar al profesional a visualizar (y así comprender mejor) el funcionamiento interno del proceso de PIR.
Características clave:
- Tres gráficos por SKU (teclado, bolígrafo y estantería).
- El gráfico de “fuerzas impulsoras” visualiza las principales fuerzas impulsoras para cada decisión a nivel de unidad (para cada SKU). Por eso, el eje x solo contiene unidades de un SKU que aún no se han pedido.
- Otros dos gráficos (“incrementos de tasa de llenado” y “pronóstico de demanda probabilístico”) contienen todas las unidades de stock: stock en mano y las unidades que se pueden pedir.
7.4 Decisiones de compra clasificadas
Esta es la cuarta hoja y está dedicada a enumerar todas las decisiones de reposición factibles, ordenadas por ROI/puntuación en orden descendente. Esta lista se ordena automáticamente a partir de los datos de la hoja 2 (Decisiones de compra micro). Las decisiones factibles se muestran en relación entre sí (ver “Características clave” a continuación). Tenga en cuenta que aquí no se realiza ninguna manipulación manual de datos. Dependiendo de los cambios realizados en las entradas de las hojas 5 y 6, esta lista cambiará.
Características clave:
- Las decisiones factibles de reposición de inventario se clasifican en orden descendente (de mayor a menor) por ROI/puntuación.
- Se calcula la inversión acumulativa para las decisiones ordenadas (ver columna AA en la hoja 4).
- Al pasar el cursor sobre cada encabezado de columna se revelará una definición/nota útil.
7.5 Controlador-mini optimizador
Esta es la quinta hoja y resume las suposiciones del modelo (entradas) y las decisiones recomendadas (salidas). Los datos en las celdas manipulables se pueden cambiar para alterar las suposiciones del modelo y, por lo tanto, la salida del modelo.
Características clave:
- Tres bloques para ayudar en la demostración: “Controlador” para la manipulación manual de las entradas; “Caso base - Copia impresa” para mostrar la configuración predeterminada; y “Cambios en el escenario base” para mostrar la diferencia entre la configuración actualizada y la predeterminada (ver hoja 5).
- Un cuarto bloque (“Suposiciones del modelo”), ubicado debajo de “Controlador”, está dedicado a manipular las suposiciones de stock inicial (ver hoja 5).
- Solo se pueden cambiar los datos en las celdas manipulables.
7.6 Generadores de distribución
Esta es la sexta hoja y está dedicada a la generación de pronósticos de demanda probabilísticos. Los parámetros en las celdas manipulables se pueden cambiar, lo que resultará en la actualización de las distribuciones y la visualización de nuevos valores de demanda probabilística.
Características clave:
- Un gráfico de distribución por SKU.
- Cada SKU tiene un patrón de distribución diferente (razonamiento explicado en la sección 2.1).
- Hay una tabla a la izquierda de la serie de gráficos de distribución, dedicada a manipular los parámetros de las distribuciones.
- Solo se pueden cambiar los parámetros en las celdas manipulables.
- Al pasar el cursor sobre los encabezados de columna relevantes (en la tabla) se revelará una definición/nota útil.
Notas
-
Considera la leche y el chocolate. El primero es un producto de margen bajo, pero se considera un producto básico, mientras que el segundo es discrecional y tiene márgenes de beneficio más altos. Las personas tienden a comprar productos básicos y productos discrecionales juntos, pero la penalización por no tener leche es diferente a la de no tener chocolate. Un cliente puede cambiar un producto discrecional (galletas) por otro (chocolate) en caso de falta de stock, pero si no puede comprar un producto básico (leche), es posible que salga de la tienda por completo. Por eso, la cobertura de falta de stock sería mayor para la leche que para el chocolate, independientemente del margen de beneficio bruto. Desde nuestro punto de vista, la cobertura de falta de stock es una recompensa en lugar de una penalización, ya que tiene como objetivo permitir mayores ventas. ↩︎
-
Tres productos son suficientes para ilustrar el concepto y mantener el documento conciso y comprensible. ↩︎
-
Los niveles de stock se vuelven probabilísticos a medida que restamos la demanda probabilística de los valores discretos de stock (la resta de un valor discreto y una distribución de probabilidad produce otra distribución de probabilidad). Todo esto sería demasiado complicado de explicar a través de Excel, ya que no está diseñado para realizar cálculos con variables aleatorias (piensa en “distribuciones de probabilidad de demanda”). ↩︎
-
Estas concesiones son necesarias para demostrar el principio general de un enfoque probabilístico. En realidad, no siempre se utilizan pedidos atrasados y los tiempos de entrega son probabilísticos y están sujetos a cambios. ↩︎
-
Por simplicidad, no aplicamos ninguna restricción de la cadena de suministro. ↩︎
-
Como se mencionó anteriormente, no es necesario editar ningún dato en las decisiones de compra micro. Toda la manipulación de datos se realiza a través de las hojas 5 y 6. ↩︎
-
En esta hoja de Excel, los impulsores económicos se expresan en dólares, aunque la moneda es irrelevante. ↩︎
-
La lista de impulsores económicos anterior no es exhaustiva y es casi seguro que los escenarios reales de reposición de inventario (y cadena de suministro) incluirán más. Esto es especialmente cierto cuando se trata de la producción de bienes y las restricciones de perecibilidad. ↩︎
-
Este impulsor es más difuso en un contexto B2C que en uno B2B. En el último, a menudo hay penalizaciones explícitas asociadas con eventos de falta de stock, como penalizaciones contractuales; en el primero, es difícil cuantificar financieramente el impacto negativo de un evento de falta de stock. En general, será alto para productos que infligen un costo negativo desproporcionado a la atractividad de un negocio (independientemente de la contribución directa del margen del SKU). La leche, como se mencionó anteriormente, no es un impulsor de margen para los supermercados, pero su ubicación estratégica (generalmente al final del supermercado) hace que los clientes recorran pasillo tras pasillo de otros productos (casi todos con márgenes más altos). Si un supermercado experimenta un evento de falta de stock con este producto básico (uno que las personas tienden a comprar con mucha regularidad y en grandes cantidades), esto puede hacer que los clientes abandonen el supermercado, compren en otro lugar y posiblemente no regresen (si estos eventos de falta de stock son frecuentes). ↩︎
-
La probabilidad de venta se deriva de las distribuciones de probabilidad generadas en los generadores de distribución (hoja 6). ↩︎
-
El costo continuo por no vender y tener que almacenar una unidad no vendida de un SKU. ↩︎
-
La inversión es, en este escenario, la misma que el precio de compra, pero solo porque nuestras decisiones de compra no están limitadas por MOQs o multiplicadores de lote. ↩︎
-
La forma más fácil de hacer esto es establecer el factor de agresividad (columna S en la Figura 12) en cero, lo cual una empresa podría hacer si decidiera que un evento de falta de stock no tiene impactos negativos. Un consejo gratuito: definitivamente los tiene. ↩︎
-
Por ejemplo, nuestro presupuesto predeterminado es de $500, por lo que terminaríamos nuestras decisiones de compra en la celda 40 (ver Figura 13), ya que la celda 41 tiene un valor de $506.88 y está más allá de nuestro presupuesto. Luego agregaríamos números por producto, lo que constituiría nuestra lista de compra (ver Salida - Recomendación de compra en Control Tower, según la Figura 2). Como se mencionó anteriormente, se puede editar el presupuesto preestablecido de $500 (ver Figura 2 para las instrucciones) a cualquier valor entre $0 y $1450. Esto demostrará cómo cambia la lista de compra con diferentes restricciones presupuestarias. Independientemente de las limitaciones financieras, las Decisiones de compra clasificadas identificarán la mejor combinación posible de decisiones de inventario, desde una perspectiva de ROI, para todas las filas entre el rango 1 y el punto de terminación. ↩︎