Inteligencia de Negocios (BI)
La Inteligencia de Negocios (Business Intelligence, BI) se refiere a una clase de software empresarial dedicado a la producción de informes analíticos basados principalmente en los datos transaccionales recopilados a través de los diversos sistemas empresariales que la empresa utiliza para operar. El BI tiene como objetivo ofrecer capacidades de informes de autoservicio a los usuarios que no son especialistas en tecnología de la información. Estas capacidades de autoservicio pueden variar desde ajustar parámetros en informes existentes hasta la creación de informes completamente nuevos. La mayoría de las grandes empresas tienen al menos un sistema de BI en funcionamiento junto con sus sistemas transaccionales, que a menudo incluyen un ERP.
Origen y motivación
El informe analítico moderno surgió con los primeros pronosticadores económicos1 2, predominantemente en los Estados Unidos, a principios del siglo XX. Esta primera iteración resultó extremadamente popular, recibiendo atención de la prensa general y amplia circulación. Esta popularidad demostró un gran interés en informes cuantitativos de alta densidad de información. Durante la década de 1980, muchas grandes empresas comenzaron a preservar sus transacciones comerciales como registros electrónicos, almacenados en bases de datos transaccionales, generalmente aprovechando algunas soluciones ERP tempranas. Estas soluciones de ERP estaban destinadas principalmente a agilizar los procesos existentes, mejorando la productividad y la confiabilidad. Sin embargo, muchos entendieron el enorme potencial sin explotar de estos registros y, en 1983, SAP introdujo el lenguaje de programación ABAP3, dedicado a la generación de informes basados en los datos recopilados dentro del propio ERP.
Sin embargo, los sistemas de bases de datos relacionales, como se vendían típicamente en la década de 1980, presentaban dos limitaciones importantes en lo que respecta a la producción de informes analíticos. En primer lugar, el diseño de los informes debía ser realizado por especialistas en tecnología de la información altamente capacitados. Esto hacía que el proceso fuera lento y costoso, limitando severamente la diversidad de informes que se podían introducir. En segundo lugar, la generación de los informes era muy exigente para el hardware informático. Los informes generalmente solo se podían producir durante la noche (y en lotes), cuando las operaciones de la empresa habían cesado. En cierta medida, esto reflejaba las limitaciones del hardware informático de la época, pero también reflejaba limitaciones de software.
A principios de la década de 1990, el progreso del hardware informático permitió que surgiera una clase diferente de soluciones de software4, soluciones de Inteligencia de Negocios. El costo de la RAM (memoria de acceso aleatorio) había estado disminuyendo constantemente, mientras que su capacidad de almacenamiento había estado aumentando constantemente. Como resultado, almacenar una versión especializada y más compacta de los datos comerciales en memoria (en RAM) para un acceso inmediato se convirtió en una solución viable, desde puntos de vista tecnológicos y económicos. Estos avances abordaron las dos limitaciones principales de los sistemas de informes implementados una década antes: las nuevas interfaces de software eran mucho más accesibles para los no especialistas; y los nuevos back-ends de software, que presentaban tecnologías OLAP (discutidas a continuación), eliminaron algunas de las mayores limitaciones de TI. Gracias a estos avances, a fines de la década, las soluciones de BI se habían vuelto comunes entre las grandes empresas.
A medida que el hardware informático continuó progresando, surgió una nueva generación de herramientas de BI5 a fines de la década de 2000. Los sistemas de bases de datos relacionales de la década de 1980, que eran incapaces de producir informes de manera conveniente, se volvieron cada vez más capaces de almacenar todo el historial transaccional de un negocio en RAM. Como resultado, las consultas analíticas complejas podían completarse en segundos sin necesidad de un back-end OLAP dedicado. Por lo tanto, el enfoque de las soluciones de BI se desplazó al front-end, ofreciendo interfaces de usuario web aún más accesibles, predominantemente SaaS (software como servicio), y presentando paneles interactivos cada vez más interactivos que aprovechaban la versatilidad del back-end relacional.
OLAP y cubos multidimensionales
OLAP significa procesamiento analítico en línea. OLAP está asociado con el diseño del back-end de una solución de BI. El término, acuñado en 1993 por Edgar Codd, reúne una serie de ideas de diseño de software6, la mayoría de las cuales se remontan a la década de 1990, y algunas incluso a la década de 1960. Estas ideas de diseño fueron fundamentales en la aparición de BI como una clase distinta de productos de software en la década de 1990. OLAP abordó el desafío de poder producir informes analíticos actualizados de manera oportuna, incluso cuando la cantidad de datos involucrados en la producción del informe era demasiado grande para procesarse rápidamente.
La técnica más sencilla para producir un informe analítico actualizado implica leer los datos al menos una vez. Sin embargo, si el conjunto de datos es tan grande7 que leerlo en su totalidad lleva horas (si no días), entonces producir un informe actualizado también requerirá horas o días. Por lo tanto, para producir un informe actualizado en segundos, la técnica no puede implicar volver a leer el conjunto de datos completo cada vez que se solicite una actualización del informe.
OLAP propone aprovechar estructuras de datos más pequeñas y compactas que reflejen los informes de interés. Estas estructuras de datos específicas están diseñadas para actualizarse de forma incremental a medida que haya datos más recientes disponibles. Como resultado, cuando se solicita un informe actualizado, el sistema de BI no tiene que volver a leer todo el conjunto de datos históricos, sino solo la estructura de datos compacta que contiene toda la información necesaria para generar el informe. Además, si la estructura de datos es lo suficientemente pequeña, se puede mantener en memoria (en RAM) y, por lo tanto, se puede acceder más rápido que el almacenamiento persistente utilizado para los datos transaccionales.
Consideremos el siguiente ejemplo: imaginemos una red minorista que opera 100 hipermercados. El director financiero desea un informe con las ventas totales en euros por tienda y día durante los últimos 3 años. Los datos de ventas históricos en bruto de los últimos 3 años representan más de mil millones de líneas de datos (cada código de barras escaneado en cada tienda durante este período) y más de 50 GB en su formato tabular en bruto. Sin embargo, una tabla con 100 columnas (1 por hipermercado) y 1095 líneas (3 años * 365 días) tiene un tamaño inferior a 0.5 MB (a una tasa de 4 bytes por número). Además, cada vez que ocurre una transacción, las celdas correspondientes en la tabla se pueden actualizar en consecuencia. Crear y mantener una tabla así ilustra cómo se ve un sistema OLAP por debajo.
Las estructuras de datos compactas descritas anteriormente suelen adoptar la forma de un cubo OLAP, también llamado cubo multidimensional. Las celdas existen en el cubo en la intersección de las dimensiones discretas que definen la estructura general del cubo. Cada celda contiene una medida (o valor) extraído de los datos transaccionales originales, a menudo denominados tabla de hechos. Esta estructura de datos es similar a los arreglos multidimensionales que se encuentran en la mayoría de los lenguajes de programación populares. El cubo OLAP se presta a operaciones eficientes de proyección o agregación a lo largo de las dimensiones (como sumar y promediar), siempre y cuando el cubo sea lo suficientemente pequeño como para caber en la memoria de la computadora.
Informes interactivos y visualización de datos
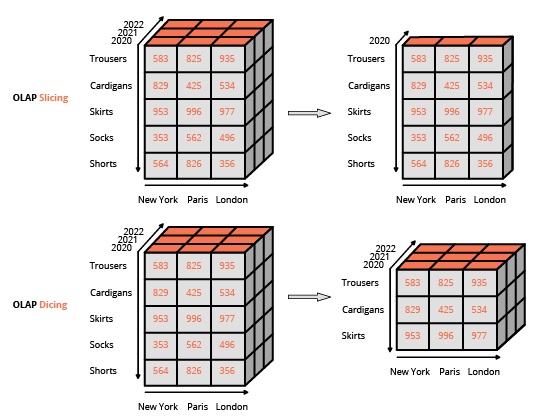
Hacer que las capacidades de informes sean accesibles para usuarios finales que no son especialistas en tecnología fue un factor clave en la adopción de herramientas de inteligencia empresarial (BI, por sus siglas en inglés). Como tal, la tecnología adoptó un diseño WYSIWYG (lo que ves es lo que obtienes), basándose en interfaces de usuario intuitivas. Este enfoque difiere del enfoque habitual para interactuar con una base de datos relacional, que consiste en componer consultas utilizando un lenguaje especializado (como SQL). La interfaz habitual para manipular un cubo OLAP es una interfaz de matriz, como las tablas dinámicas en un programa de hojas de cálculo, que permite a los usuarios aplicar filtros (llamados slice and dice en la terminología de BI) y realizar agregaciones (promedio, mínimo, máximo, suma, etc.).
A excepción del procesamiento de conjuntos de datos especialmente grandes, la necesidad de cubos OLAP disminuyó a fines de la década de 2000 en paralelo con los grandes avances en hardware informático. Se introdujeron nuevas herramientas de BI “delgadas” con un enfoque exclusivo en el front-end. Las herramientas de BI delgadas fueron diseñadas principalmente para interactuar con bases de datos relacionales, a diferencia de sus predecesoras “gruesas” que aprovechaban back-ends integrados con cubos OLAP. Esta evolución fue posible porque el rendimiento de las bases de datos relacionales, en ese momento, generalmente permitía ejecutar consultas complejas sobre todo el conjunto de datos en segundos, siempre y cuando el conjunto de datos se mantuviera por debajo de un cierto tamaño. Las herramientas de BI delgadas se pueden ver como editores WYSIWYG unificados para los diversos dialectos de SQL que admitían. (De hecho, bajo el capó, estas herramientas de BI generan consultas SQL). El principal desafío técnico fue la optimización de las consultas generadas, con el fin de minimizar el tiempo de respuesta de la base de datos relacional subyacente.
Las capacidades de visualización de datos de las herramientas de BI eran en gran medida una cuestión de presentación de datos en el lado del cliente, ya sea a través de una aplicación de escritorio o web. Las capacidades de presentación progresaron constantemente hasta la década de 2000, cuando el hardware del usuario final (por ejemplo, estaciones de trabajo y portátiles) comenzó a superar ampliamente (en términos computacionales) lo que se necesitaba para fines de visualización de datos. Hoy en día, incluso las visualizaciones de datos más elaboradas son procesos poco exigentes, eclipsados en escala por el consumo de recursos informáticos asociados con la extracción y transformación de los datos subyacentes que se están visualizando.
El impacto organizativo de la inteligencia empresarial
Si bien la facilidad de acceso ha sido un factor decisivo para la adopción de la mayoría de las herramientas de BI, navegar por el panorama de datos de las grandes empresas es difícil, si solo se debe a la diversidad de datos disponibles. Además, incluso si la herramienta de BI es bastante accesible, la lógica de informes que las empresas implementan a través de las herramientas de BI tiende a reflejar la complejidad del negocio y, como resultado, la lógica en sí puede ser mucho menos accesible que la herramienta que respalda su ejecución.
Como resultado, la adopción de herramientas de BI lleva, en la mayoría de las grandes empresas, a la creación de equipos de análisis dedicados, que generalmente operan como una función de soporte junto con el departamento de TI. Como predijo la Ley de Parkinson, el trabajo se expande para llenar el tiempo disponible para su finalización; estos equipos tienden a expandirse con el tiempo junto con la cantidad de informes generados, independientemente de los beneficios obtenidos (percibidos o reales) por la empresa al acceder a dichos informes.
Límites técnicos de BI
Como suele ser el caso, hay un compromiso entre las virtudes cuando se trata de herramientas de BI, lo que significa que una mayor facilidad de acceso conlleva el costo de la expresividad; en este caso, las transformaciones aplicadas a los datos se limitan a una clase relativamente estrecha de filtros y agregaciones. Esta es la primera limitación importante, ya que muchas, si no la mayoría, de las preguntas comerciales no se pueden abordar con esos operadores (por ejemplo, ¿cuál es el riesgo de abandono de un cliente?). Por supuesto, es posible introducir operadores avanzados en la interfaz de usuario de BI, sin embargo, estas características “avanzadas” contradicen 8 el propósito inicial de hacer que la herramienta sea fácilmente accesible para usuarios no técnicos. Como tal, diseñar consultas de datos avanzadas no es diferente de construir software, una tarea que resulta inherentemente difícil. A modo de evidencia anecdótica, la mayoría de las herramientas de BI ofrecen la posibilidad de escribir consultas “en bruto” (generalmente en SQL o un dialecto similar a SQL), volviendo al camino técnico que se suponía que la herramienta eliminaría.
La segunda limitación importante es el rendimiento. Esta limitación se presenta en dos sabores distintos para las herramientas de BI delgadas y gruesas, respectivamente. Las herramientas de BI delgadas suelen incluir una lógica sofisticada para optimizar las consultas de la base de datos que generan. Sin embargo, estas herramientas están limitadas en última instancia por el rendimiento que puede ofrecer la base de datos que sirve como backend. Una consulta aparentemente simple puede resultar ineficiente de ejecutar, lo que lleva a tiempos de respuesta largos. Un ingeniero de bases de datos ciertamente puede modificar y mejorar la base de datos para abordar esta preocupación. Sin embargo, una vez más, esta solución contradice el objetivo inicial de mantener la herramienta de BI accesible para usuarios no técnicos.
Las herramientas de BI gruesas tienen su rendimiento limitado por el diseño de los cubos OLAP mismos. En primer lugar, la cantidad de RAM requerida para mantener un cubo multidimensional en memoria aumenta rápidamente a medida que aumentan las dimensiones del cubo. Incluso un número moderado de dimensiones (por ejemplo, 10) puede provocar problemas graves asociados con la huella de memoria del cubo. Más en general, los diseños en memoria (siendo los cubos OLAP los más frecuentes) suelen sufrir problemas relacionados con la memoria.
Además, el cubo es una representación perdida de los datos transaccionales originales: ninguna analítica realizada con el cubo puede recuperar información que se haya perdido en primer lugar. Recuerde el ejemplo del hipermercado. En tal escenario, las cestas no se pueden representar en un cubo. Por lo tanto, se pierde la información de “compra conjunta”. El diseño general del “cubo” de OLAP limita severamente qué datos se pueden representar; sin embargo, esta limitación es precisamente lo que hace posible la propiedad “en línea” en primer lugar.
Límites empresariales de BI
La introducción de herramientas de BI en una empresa es menos transformadora de lo que puede parecer. En pocas palabras, producir números, en sí mismos, no tiene valor para la empresa si no se adjunta ninguna acción a esos números. El diseño mismo de las herramientas de BI enfatiza una producción “ilimitada” de informes, pero el diseño no respalda ningún curso de acción real. De hecho, en la mayoría de las situaciones, la escasa expresividad de las herramientas de BI resulta demasiado limitante cuando se trata de automatizar cualquier cosa basada en los informes de BI.
Además, la herramienta de BI tiende a exacerbar las tendencias burocráticas de las grandes empresas. Pruebas anecdóticas, números aproximados y juicio sólido a menudo son suficientes para establecer prioridades para una empresa. Sin embargo, la existencia de una herramienta analítica autoservicio, como BI, brinda amplias oportunidades para procrastinar y enturbiar las aguas con una corriente incesante de métricas cuestionables y no accionables.
Las herramientas de BI son vulnerables a los problemas de diseño por comité donde las ideas de todos se incluyen en el proyecto. La naturaleza autoservicio de la herramienta enfatiza un enfoque ampliamente inclusivo cuando se trata de la introducción de nuevos informes. Como resultado, la complejidad del panorama de informes tiende a crecer con el tiempo, independientemente de la complejidad empresarial que se supone que esos informes deben reflejar. El término métricas de vanidad se ha vuelto ampliamente utilizado para reflejar métricas, generalmente implementadas a través de una herramienta de BI, como estas que no contribuyen a los resultados finales de una empresa.
Opinión de Lokad
Teniendo en cuenta las capacidades del hardware informático moderno, usar un sistema de informes para producir 1 millón de números al día es fácil; producir 10 números al día que valgan la pena leer es difícil. Si bien una herramienta de BI utilizada en pequeñas dosis es algo bueno para la mayoría de las empresas, en dosis más altas se convierte en un veneno.
En la práctica, solo se pueden obtener tantos conocimientos de BI. La introducción de más y más informes resulta en rendimientos decrecientes rápidamente en términos de nuevos (o mejorados) conocimientos obtenidos a través de cada informe adicional. Recuerde, la profundidad del análisis de datos accesible desde una herramienta de BI está limitada por diseño, ya que las consultas deben seguir siendo fácilmente accesibles para no especialistas a través de la interfaz de usuario.
Además, incluso cuando se adquiere un nuevo conocimiento a través de los datos, no implica que la empresa pueda convertirlo en algo accionable. BI es, en su esencia, una tecnología de informes: no enfatiza ninguna llamada a la acción para la empresa. El paradigma de BI no está orientado a automatizar decisiones comerciales (ni siquiera las mundanas).
La plataforma de Lokad cuenta con amplias capacidades de informes personalizados, al igual que BI. Sin embargo, a diferencia de BI, Lokad está dirigido a la optimización de decisiones comerciales, más específicamente aquellas relacionadas con la cadena de suministro. En la práctica, recomendamos tener un Supply Chain Scientist a cargo del diseño y posterior mantenimiento de la receta numérica que genera, a través de Lokad, las decisiones de la cadena de suministro de interés.
Notas
-
Fortune Tellers: The Story of America’s First Economic Forecasters, por Walter Friedman (2013). ↩︎
-
A Selection of Early Forecasting & Business Charts, por Walter Friedman (2014) (PDF) ↩︎
-
ABAP es un lenguaje de programación lanzado por SAP en 1983 que significa Allgemeiner Berichts-Aufbereitungs-Prozessor, en alemán “procesador general de preparación de informes”. Este lenguaje se introdujo como precursor de los sistemas de BI para complementar el ERP (también llamado SAP) con capacidades de informes. El objetivo de ABAP era aliviar la sobrecarga de ingeniería asociada con la implementación de informes personalizados. En la década de 1990, ABAP se reutilizó como un lenguaje de configuración y extensión para el propio ERP. El lenguaje también se renombró en inglés como Advanced Business Application Programming para reflejar este cambio de enfoque. ↩︎
-
BusinessObjects, fundada en 1990 y adquirida por SAP en 2008, es el arquetipo de las soluciones de BI que surgieron en la década de 1990. ↩︎
-
Tableau, fundada en 2003 y adquirida por Salesforce en 2019, es el arquetipo de las soluciones de BI que surgieron en la década de 2000. ↩︎
-
The origins of today’s OLAP products, Nigel Pendse, última actualización en agosto de 2007, ↩︎
-
El hardware informático ha estado progresando constantemente desde la década de 1950. Sin embargo, cada vez que se volvió más barato procesar más datos, también se volvió más barato almacenar más datos. Como resultado, desde la década de 1970, la cantidad de datos comerciales ha estado creciendo casi tan rápido como las capacidades del hardware informático. Por lo tanto, la noción de “demasiados datos” es en gran medida un objetivo en movimiento. ↩︎
-
A fines de la década de 1990 y principios de la década de 2000, muchas empresas de software intentaron, sin éxito, reemplazar los lenguajes de programación con herramientas visuales. Véase también, Lego Programming por Joel Spolsky, diciembre de 2006 ↩︎