Stock de seguridad
El stock de seguridad es un método de optimización de inventario que indica cuánto inventario debe mantenerse más allá de la demanda esperada para alcanzar un objetivo de nivel de servicio dado. El stock adicional actúa como un buffer de “seguridad”, de ahí el nombre, para proteger a la empresa contra futuras fluctuaciones esperadas. La fórmula del stock de seguridad depende tanto de la demanda futura esperada como del tiempo de entrega futuro esperado. Se asume que la incertidumbre está distribuida normalmente para ambos factores. La fórmula del stock de seguridad es ubicua en la mayoría de los sistemas de gestión de inventario, incluyendo la mayoría de los notables ERPs y MRPs.
Actualización julio de 2020: El enfoque detallado a continuación es el de la cadena de suministro “de libro de texto”, desafortunadamente, también resulta ser muy disfuncional. En particular, ni la demanda futura ni el tiempo de entrega futuro están distribuidos normalmente (es decir, no son gaussianos). Además, toda la perspectiva pasa por alto por completo el hecho de que todos los SKU que pueden ser ordenados o producidos por la empresa compiten por los mismos recursos. Recomendamos encarecidamente no utilizar ningún modelo de stock de seguridad en lo que respecta a las cadenas de suministro reales.
Público objetivo: Este documento está dirigido principalmente a profesionales de la cadena de suministro en el sector minorista o manufacturero. Sin embargo, este documento también es útil para los editores de software de contabilidad / ERP / comercio electrónico que deseen ampliar sus aplicaciones con funciones de gestión de stock.
Hemos intentado mantener los requisitos matemáticos lo más bajos posible, sin embargo, no podemos evitar por completo todas las fórmulas, ya que el propósito preciso de este documento es ser una guía práctica que explique cómo calcular el stock de seguridad.
Descargar: calcular-stocks-seguridad.xls (Microsoft Excel Spreadsheet)
Introducción
La gestión de inventario es un compromiso financiero entre los costos de inventario y los costos de faltante de stock. Cuanto más stock, más capital de trabajo se necesita y más depreciación de stock se obtiene. Por otro lado, si no tienes suficiente stock, tendrás faltantes de inventario, lo que significa ventas potenciales perdidas y la posibilidad de interrumpir todo el proceso de producción.
El stock de inventario depende fundamentalmente de dos factores:
- demanda de tiempo de entrega: la cantidad de artículos que se consumirán o comprarán.
- tiempo de entrega: el retraso entre la decisión de reordenar y la disponibilidad renovada.
Sin embargo, estos dos factores están sujetos a incertidumbres:
- variaciones en la demanda: los comportamientos de los clientes pueden evolucionar de manera bastante impredecible.
- variaciones en el tiempo de entrega: los proveedores o transportistas pueden enfrentarse a dificultades no planificadas.
Decidir el nivel de stock de seguridad es equivalente implícitamente a hacer un equilibrio entre esos costos considerando las incertidumbres.
El equilibrio entre los costos de inventario y los costos de faltante de stock depende mucho del negocio. Por lo tanto, en lugar de considerar esos costos directamente, ahora introduciremos la noción clásica de nivel de servicio.
El nivel de servicio expresa la probabilidad de que un cierto nivel de stock de seguridad no conduzca a un faltante de stock. Naturalmente, cuando se aumentan los stocks de seguridad, el nivel de servicio también aumenta. Cuando los stocks de seguridad son muy grandes, el nivel de servicio tiende hacia el 100% (es decir, una probabilidad de cero de encontrar un faltante de stock).
Elegir el nivel de servicio, es decir, la probabilidad aceptable de faltante de stock, está más allá del alcance de esta guía, pero tenemos una guía separada sobre cómo calcular los niveles de servicio óptimos.
Modelo de reabastecimiento de inventario
El punto de reorden es la cantidad de stock que debe desencadenar un pedido. Si no hubiera incertidumbre (es decir, si se conociera perfectamente la demanda futura y el suministro fuera perfectamente confiable), el punto de reorden sería simplemente igual a la demanda total pronosticada durante el tiempo de entrega, también llamada demanda de tiempo de entrega.
En la práctica, debido a las incertidumbres, tenemos
punto de reorden = demanda de tiempo de entrega + stock de seguridad
Si asumimos que los pronósticos no están sesgados (estadísticamente hablando), no tener stocks de seguridad llevaría a un nivel de servicio del 50%. De hecho, los pronósticos no sesgados significan que hay tantas posibilidades de que la demanda futura sea mayor o menor que la demanda de tiempo de entrega (recuerde que la demanda de tiempo de entrega es solo un valor pronosticado).
Precaución: los pronósticos pueden ser no sesgados sin ser exactos. El sesgo indica un error sistemático del modelo de pronóstico (por ejemplo, siempre sobreestimar la demanda en un 20%).
Distribución normal del error
En este punto, necesitamos una forma de representar la incertidumbre en la demanda de tiempo de entrega. A continuación, asumiremos que el error sigue una distribución normal, consulte la imagen a continuación.
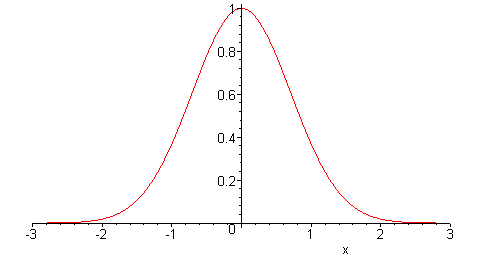
Notas estadísticas: esta suposición de distribución normal no es totalmente arbitraria. En ciertas situaciones, los estimadores estadísticos convergen a una distribución normal como se describe en el teorema del límite central. Pero esas consideraciones están más allá del alcance de esta guía.
Una distribución normal solo está definida por dos parámetros: su media y su varianza. Dado que asumimos que los pronósticos no están sesgados, asumimos que la media de la distribución del error es cero, lo cual no significa que estemos asumiendo un error cero.
Determinar la varianza del error de pronóstico es una tarea más delicada. Lokad, al igual que la mayoría de las herramientas de pronóstico, proporciona estimaciones de MAPE (Error Porcentual Absoluto Medio) asociadas a sus pronósticos. Para ser completos, explicaremos cómo se pueden utilizar heurísticas simples para superar este problema.
En particular, la varianza dentro de los datos históricos se puede utilizar como una buena heurística para estimar la varianza del error de pronóstico. David Piasecki también sugiere utilizar la demanda pronosticada en lugar de la demanda media en la expresión de la varianza, es decir,
donde $$E$$ es el operador media, $$y_t$$ es la demanda histórica para el período $$t$$ (normalmente la cantidad de ventas) y $$y’$$ es la demanda pronosticada.
La idea clave detrás de esta suposición es que el error de pronóstico está muy a menudo correlacionado con la cantidad de variación esperada: a mayor variación futura, mayor será el error en los pronósticos.
De hecho, el cálculo de esta varianza de error implica algunas sutilezas que se tratarán con más detalle a continuación.
Expresión del stock de seguridad
En este punto, hemos determinado tanto la media como la varianza, por lo que se conoce la distribución del error. Ahora debemos calcular el nivel de error aceptable dentro de esta distribución. Aquí arriba, hemos introducido la noción de nivel de servicio (un porcentaje) para hacer eso.
Notas: Estamos asumiendo un tiempo de entrega estático. Sin embargo, se puede utilizar un enfoque muy similar para un tiempo de entrega variable. Consulte
Para convertir el nivel de servicio en un nivel de error, también llamado factor de servicio, debemos utilizar la distribución normal acumulada inversa (a veces también llamada distribución normal inversa) (consulte NORMSINV para la función correspondiente en Excel). Aunque pueda parecer complicado, no lo es, sugerimos echar un vistazo a la applet de distribución normal para obtener una idea más visual. Como se puede ver, la función acumulativa transforma el porcentaje en un área bajo la curva, el umbral del eje X corresponde al valor del factor de servicio.
L7 De manera intuitiva, calculamos
stock de seguridad = desviación estándar del error * factor de servicio
Más formalmente, sea $$S$$ el stock de seguridad, tenemos
donde $$\sigma$$ es la desviación estándar (es decir, la raíz cuadrada de $$\sigma^2$$ la varianza definida anteriormente), $$cdf$$ la distribución normal acumulada normalizada (media cero y varianza igual a uno) y $$P$$ el nivel de servicio.
Recordando que
punto de reorden = demanda de tiempo de entrega + stock de seguridad
Sea $$R$$ el punto de reorden, tenemos
Coincidencia de tiempo de entrega y período de pronóstico
Hasta ahora, hemos estado asumiendo simplemente que para un determinado tiempo de entrega, éramos capaces de producir directamente el pronóstico de la demanda futura correspondiente. En la práctica, no funciona exactamente así. El análisis de los datos históricos generalmente comienza agregando los datos en períodos de tiempo (generalmente semanas o meses).
Sin embargo, el período elegido puede no coincidir exactamente con el tiempo de entrega; por lo tanto, se requieren algunos cálculos adicionales para expresar la demanda del tiempo de entrega y su varianza asociada (considerando que todavía estamos asumiendo una distribución normal para el error de pronóstico, como se detalla en la sección anterior).
De manera intuitiva, la demanda del tiempo de entrega se puede calcular como la suma de los valores pronosticados para los períodos futuros que se intersectan con el segmento de tiempo de entrega. Se debe tener cuidado para ajustar correctamente el último período pronosticado.
Formalmente, sea $$T$$ el período y $$L$$ el tiempo de entrega. Escribimos
donde $$k$$ es un número entero y $$0 ≤ α < 1$$. Sea $$D$$ la demanda del tiempo de entrega. Entonces, tenemos la expresión final para la demanda del tiempo de entrega
donde $$y’_n$$ es la demanda pronosticada para el $$n^{th}$$ período en el futuro.
Considerando las mismas suposiciones de distribución normal, podemos calcular la varianza del error de pronóstico como
donde $$y’$$ es el pronóstico promedio por período
Sin embargo, $$\sigma^2$$ se calcula aquí como una varianza por período mientras que necesitaríamos una varianza que coincida con el tiempo de entrega. Sea $$\sigma_{L}^2$$ la varianza ajustada por tiempo de entrega, tenemos
Finalmente, podemos expresar el punto de reorden como
Usando Excel para calcular el punto de reorden
Esta sección detalla cómo calcular el punto de reorden con Microsoft Excel. Sugerimos echar un vistazo a la hoja de cálculo de Excel de muestra proporcionada.
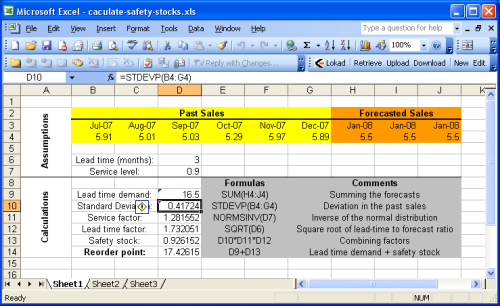
La hoja de cálculo de muestra está básicamente dividida en dos secciones: las suposiciones en la parte superior y los cálculos en la parte inferior. Los pronósticos se asumen como parte de las suposiciones porque el pronóstico de ventas (o demanda) está fuera del alcance de esta guía. Puede consultar nuestro tutorial sobre pronósticos de ventas con Microsoft Excel para obtener más detalles.
La mayoría de las fórmulas presentadas en la sección anterior son operaciones muy simples (sumas, multiplicaciones) que son muy fáciles de realizar con Microsoft Excel. Sin embargo, hay dos funciones destacables
- NORMSINV (Microsoft KB): estima la distribución normal acumulativa, denominada cdf anteriormente.
- STDEV (Microsoft KB): estima la desviación estándar, denominada $$σ$$ anteriormente. Recordamos que la desviación estándar $$σ$$ es la raíz cuadrada de la varianza $${σ^2}$$.
Por simplicidad, la primera hoja no implementa la heurística $${σ^2 = E[ (y_t - y’)^2 ]}$$ al calcular el factor de servicio. Este enfoque se implementa en la Hoja2 (segunda hoja de cálculo del documento de Excel). Dado que hemos asumido pronósticos estacionarios en el ejemplo, el punto de reorden permanece idéntico con o sin esta heurística.
Recursos
Inventory Management and Production Planning and Scheduling, Edward A. Silver, David F. Pyke, Rein Peterson, Wiley; 3ª edición, 1998