PROGRAMMIERPARADIGMEN FÜR DIE LIEFERKETTE (ZUSAMMENFASSUNG DER VORLESUNG 1.4)
Lieferkettenprobleme sind komplex und der Versuch, sie ohne geeignete Programmierungswerkzeuge in einem Unternehmen im großen Maßstab anzugehen, erweist sich als kostspielige Lernerfahrung. Eine effektive Optimierung der Lieferkette - ein verteiltes Netzwerk von physischen und abstrakten Komplexitäten - erfordert eine Reihe moderner, agiler und innovativer Programmierparadigmen. Diese Paradigmen sind entscheidend für die erfolgreiche Identifizierung, Berücksichtigung und Lösung der vielfältigen Probleme, die in der Lieferkette inhärent sind.
Vorlesung ansehen

Statische Analyse
Man muss kein Computerprogrammierer sein, um wie einer zu denken, und die ordnungsgemäße Analyse von Lieferkettenproblemen lässt sich am besten mit einer programmierorientierten Denkweise und nicht nur mit Programmierungswerkzeugen bewältigen. Traditionelle Softwarelösungen (wie ERP-Systeme) sind so konzipiert, dass Probleme zur Laufzeit und nicht zur Kompilierzeit1 behandelt werden.
Dies ist der Unterschied zwischen einer reaktiven Lösung und einer proaktiven Lösung. Diese Unterscheidung ist entscheidend, da reaktive Lösungen in finanzieller und bandbreitenmäßiger Hinsicht tendenziell viel teurer sind als proaktive Lösungen. Diese weitgehend vermeidbaren Kosten sind genau das, was eine programmierorientierte Denkweise zu vermeiden versucht, und die statische Analyse ist der Ausdruck dieses Rahmens.
Statische Analyse beinhaltet die Inspektion eines Programms (in diesem Fall der Optimierung), ohne es auszuführen, um potenzielle Probleme vor ihrer Auswirkung auf die Produktion zu identifizieren. Lokad verwendet zur statischen Analyse Envision, seine domänenspezifische Sprache (DSL). Dies ermöglicht die Identifizierung und Korrektur von Fehlern auf Designebene (in der Programmiersprache) so schnell und bequem wie möglich.
Betrachten Sie ein Unternehmen, das dabei ist, ein Lagerhaus zu bauen. Man errichtet nicht das Lagerhaus und überlegt sich dann die Anordnung. Vielmehr wird die strategische Anordnung von Gängen, Regalen und Laderampen im Voraus betrachtet, um potenzielle Engpässe vor dem Bau zu identifizieren. Dies ermöglicht eine optimale Gestaltung - und somit einen optimalen Fluss - innerhalb des zukünftigen Lagerhauses. Diese sorgfältige Planung ist analog zu der Art der statischen Analyse, die Lokad durch Envision durchführt.
Die hier beschriebene statische Analyse würde die zugrunde liegende Programmierung der Optimierung modellieren und jegliches potenziell adversative Verhalten innerhalb des Rezepts identifizieren, bevor es installiert wird. Diese adversativen Tendenzen könnten einen Fehler beinhalten, der zu einer versehentlichen Bestellung von viel mehr Lagerbestand führt als nötig. Als Ergebnis würden solche Fehler aus dem Code entfernt, bevor sie die Chance haben, Chaos anzurichten.
Array-Programmierung
In der Optimierung der Supply Chain ist eine strikte Zeitplanung unerlässlich. Zum Beispiel müssen in einer Einzelhandelskette Daten innerhalb eines 60-minütigen Zeitfensters konsolidiert, optimiert und an das Lagerverwaltungssystem weitergegeben werden. Wenn Berechnungen zu lange dauern, kann die gesamte Ausführung der Supply Chain gefährdet sein. Die Array-Programmierung löst dieses Problem, indem sie bestimmte Klassen von Programmierfehlern eliminiert und die Berechnungsdauer garantiert, wodurch Supply Chain-Experten einen vorhersehbaren Zeitrahmen für die Datenverarbeitung erhalten.
Auch bekannt als Data Frame-Programmierung ermöglicht dieser Ansatz Operationen direkt auf Datenarrays durchzuführen, anstatt isolierte Daten zu verwenden. Lokad erreicht dies durch die Nutzung von Envision, seiner DSL. Die Array-Programmierung kann die Datenmanipulation und -analyse vereinfachen, indem Operationen auf gesamte Spalten von Daten anstatt einzelner Einträge in jeder Tabelle durchgeführt werden. Dies erhöht die Effizienz der Analyse dramatisch und reduziert gleichzeitig die Wahrscheinlichkeit von Fehlern in der Programmierung.
Betrachten Sie einen Lagerhausmanager, der zwei Listen hat: Liste A sind die aktuellen Lagerbestände und Liste B sind eingehende Lieferungen für die Produkte in Liste A. Anstatt jedes Produkt einzeln durchzugehen und die eingehenden Lieferungen (Liste B) manuell zu den aktuellen Lagerbeständen (Liste A) hinzuzufügen, wäre eine effizientere Methode, beide Listen gleichzeitig zu verarbeiten, um die Lagerbestände für alle Produkte auf einmal zu aktualisieren. Dies würde Zeit und Aufwand sparen und ist im Wesentlichen das Ziel der Array-Programmierung2.
In der Realität erleichtert die Array-Programmierung die Parallelisierung und Verteilung der Berechnung der großen Datenmengen, die bei der Optimierung der Supply Chain involviert sind. Durch die Verteilung der Berechnung auf mehrere Maschinen können Kosten reduziert und Ausführungszeiten verkürzt werden.
Hardware-Kompatibilität
Einer der Hauptengpässe bei der Optimierung der Supply Chain ist die begrenzte Anzahl von Supply Chain Scientists. Diese Wissenschaftler sind dafür verantwortlich, numerische Rezepte zu erstellen, die die Strategien der Kunden sowie die antagonistischen Machenschaften der Konkurrenten berücksichtigen, um handlungsrelevante Erkenntnisse zu liefern.
Diese Experten sind nicht nur schwer zu finden, sondern müssen oft mehrere Hardware-Hürden überwinden, die sie von der schnellen Ausführung ihrer Aufgaben trennen. Hardware-Kompatibilität - die Fähigkeit verschiedener Komponenten innerhalb eines Systems, sich zu verbinden und zusammenzuarbeiten - ist entscheidend, um diese Hindernisse zu beseitigen. Hier werden drei grundlegende Ressourcen für die Berechnung betrachtet:
- Rechenleistung: Die Verarbeitungsleistung eines Computers, bereitgestellt entweder durch die CPU oder die GPU.
- Speicher: Die Speicherkapazität eines Computers, gehostet durch RAM oder ROM.
- Bandbreite: Die maximale Rate, mit der Informationen (Daten) zwischen verschiedenen Teilen eines Computers oder über ein Netzwerk von Computern übertragen werden können.
Die Verarbeitung großer Datensätze ist im Allgemeinen ein zeitaufwändiger Prozess, der zu einer geringeren Produktivität führt, während Ingenieure auf die Ausführung von Aufgaben warten. Bei der Optimierung der Supply Chain könnte man Code-Schnipsel (die routinemäßige Zwischenschritte der Berechnung repräsentieren) auf Solid-State-Laufwerken (SSDs) speichern. Dieser einfache Schritt ermöglicht es Supply Chain Scientists, ähnliche Skripte mit nur geringfügigen Änderungen viel schneller auszuführen und somit die Produktivität erheblich zu steigern.
Im obigen Beispiel wurde ein günstiger Speicherhack genutzt, um den Rechenaufwand zu verringern: Das System stellt fest, dass das gerade verarbeitete Skript nahezu identisch mit vorherigen ist, daher kann die Berechnung in Sekunden statt in zehn Minuten durchgeführt werden.
Diese Art der Hardware-Kompatibilität ermöglicht es Unternehmen, den größtmöglichen Wert aus ihren Investitionen zu ziehen.
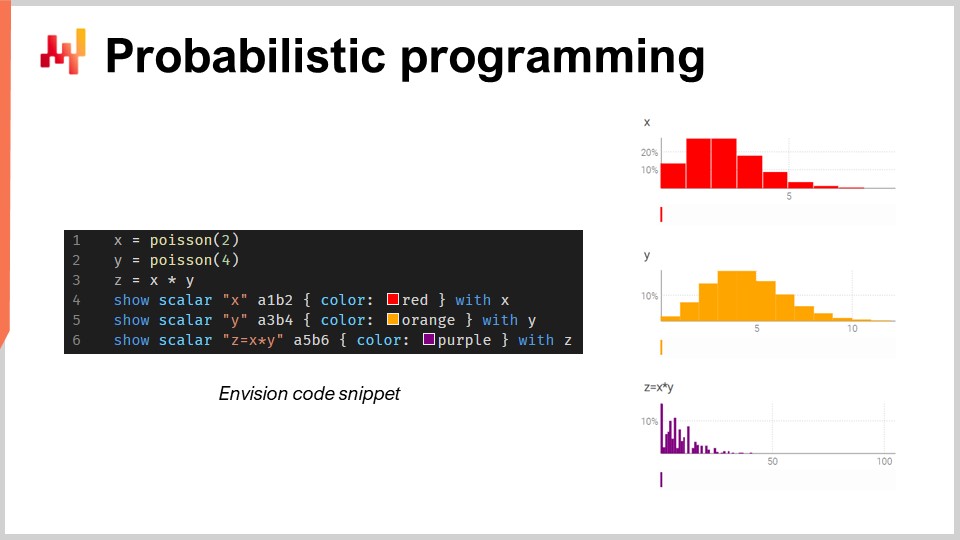
Probabilistische Programmierung
Es gibt eine unendliche Anzahl möglicher zukünftiger Ergebnisse, sie sind jedoch nicht alle gleich wahrscheinlich. Angesichts dieser irreduziblen Unsicherheit muss das/die Programmierwerkzeug(e) eine probabilistische Prognose annehmen. Obwohl Excel historisch gesehen das Fundament vieler Supply Chains war, kann es nicht in großem Maßstab mit probabilistischen Prognosen eingesetzt werden, da diese Art der Prognose die Fähigkeit erfordert, die Algebra von Zufallsvariablen zu verarbeiten3.
Kurz gesagt ist Excel hauptsächlich für deterministische Daten ausgelegt (d.h. feste Werte wie statische Ganzzahlen). Obwohl es modifiziert werden kann, um einige Wahrscheinlichkeitsfunktionen auszuführen, fehlen ihm die erweiterten Funktionen - sowie die allgemeine Flexibilität und Ausdruckskraft -, die erforderlich sind, um mit der komplexen Manipulation von Zufallsvariablen umzugehen, die bei der probabilistischen Nachfrageprognose auftreten. Stattdessen eignet sich eine probabilistische Programmiersprache wie Envision besser zur Darstellung und Verarbeitung der Unsicherheiten, mit denen man in der Supply Chain konfrontiert wird.
Betrachten wir einen Autoersatzteilhändler, der Bremsbeläge verkauft. In diesem hypothetischen Szenario müssen Kunden Bremsbeläge in Chargen von 2 oder 4 Stück kaufen, und der Händler muss diese Unsicherheit bei der Prognose der Nachfrage berücksichtigen.
Wenn der Händler Zugang zu einer probabilistischen Programmiersprache hat (anstatt einer Vielzahl von Tabellenkalkulationen), kann er den Gesamtverbrauch viel genauer schätzen, indem er die Algebra von Zufallsvariablen verwendet - was in allgemeinen Programmiersprachen normalerweise fehlt.
Differentiable Programmierung
Im Kontext der Optimierung der Supply Chain ermöglicht differentiable Programmierung dem numerischen Rezept, auf Grundlage der bereitgestellten Daten zu lernen und sich anzupassen. Differentiable Programmierung in Kombination mit einem stochastischen Gradientenabstieg ermöglicht es einem Supply Chain Scientist, komplexe Muster und Beziehungen innerhalb der Supply Chain zu entdecken. Parameter werden mit jeder neuen Programmieriteration gelernt, und dieser Prozess wird Tausende Male wiederholt. Dies geschieht, um die Diskrepanz zwischen dem aktuellen Prognosemodell und vergangenen Daten zu minimieren4.
Kannibalisierung und Substitution - innerhalb eines einzigen Katalogs - sind zwei Modellprobleme, die es in diesem Zusammenhang zu untersuchen gilt. In beiden Szenarien konkurrieren mehrere Produkte um dieselben Kunden, was eine verwirrende Schicht von Prognosekomplexität darstellt. Die Auswirkungen dieser Kräfte werden in der Regel nicht von traditionellen Zeitreihen Prognosen erfasst, die hauptsächlich den Trend, die Saisonalität und das Rauschen für ein einzelnes Produkt berücksichtigen, ohne die Möglichkeit von Interaktionen zu berücksichtigen.
Differentiable Programmierung und stochastischer Gradientenabstieg können genutzt werden, um diese Probleme anzugehen, z.B. durch Analyse der historischen Transaktionsdaten, die Kunden und Produkte verknüpfen. Envision ist in der Lage, eine solche Untersuchung - Affinitätsanalyse genannt - zwischen Kunden und Einkäufen durchzuführen, indem einfache Flachdateien mit ausreichender historischer Tiefe gelesen werden: Transaktionen, Daten, Produkte, Kunden und Kaufmengen5.
Mit nur wenigen einzigartigen Codezeilen kann Envision die Affinität zwischen einem Kunden und einem Produkt bestimmen, was es dem Supply Chain Scientist ermöglicht, das numerische Rezept, das die gewünschte Empfehlung liefert, weiter zu optimieren6.
Versionierung von Code & Daten
Ein übersehener Aspekt der langfristigen Optimierungsfähigkeit besteht darin, sicherzustellen, dass das numerische Rezept - einschließlich jeder einzelnen Codezeile und jedes Datenfragments - beschafft, verfolgt und reproduziert werden kann7. Ohne diese Versionierungsfähigkeit ist die Fähigkeit, das Rezept umzukehren, erheblich eingeschränkt, wenn unvermeidliche Ausnahmen auftreten (Heisenbugs in Computerkreisen).
Heisenbugs sind lästige Ausnahmen, die Probleme bei Optimierungsberechnungen verursachen, aber verschwinden, wenn der Prozess erneut ausgeführt wird. Dies kann sie außerordentlich schwierig zu beheben machen, was dazu führt, dass einige Initiativen scheitern und die Supply Chain zu Excel-Tabellen zurückkehrt. Um Heisenbugs zu vermeiden, ist eine vollständige Reproduzierbarkeit der Logik und Daten der Optimierung erforderlich. Dies erfordert eine Versionierung des gesamten Codes und der Daten, die im Prozess verwendet werden, um sicherzustellen, dass die Umgebung auf die genauen Bedingungen eines beliebigen früheren Zeitpunkts repliziert werden kann.
Sichere Programmierung
Neben den heimtückischen Heisenbugs birgt die zunehmende Digitalisierung der Supply Chain eine entsprechende Anfälligkeit für digitale Bedrohungen wie Cyberangriffe und Ransomware. Es gibt zwei Hauptvektoren des Chaos in dieser Hinsicht, die in der Regel unwissentlich sind: das programmierbare System oder die Systeme, die man verwendet, und die Personen, denen man erlaubt, sie zu verwenden. In Bezug auf letztere ist es sehr schwierig, versehentliche Inkompetenz zu berücksichtigen (ganz zu schweigen von absichtlicher Bosheit); in Bezug auf ersteres sind die absichtlichen Designentscheidungen, die man trifft, von entscheidender Bedeutung, um diese Minenfelder zu umgehen.
Anstatt kostbare Ressourcen in die Erhöhung des Cyber-Sicherheitsteams zu investieren (in Erwartung reaktiven Verhaltens wie Feuerbekämpfung), können kluge Entscheidungen in der Phase des Systemdesigns ganze Klassen von nachgelagerten Kopfschmerzen eliminieren. Durch Entfernen redundanter Funktionen - wie zum Beispiel einer SQL-Datenbank im Fall von Lokad - kann man vorhersehbare Katastrophen - wie zum Beispiel einen SQL-Injektionsangriff - verhindern. Ebenso bedeutet die Wahl von nur-appendierbaren Persistenzschichten (wie bei Lokad), dass das Löschen von Daten (durch Freund oder Feind) viel schwieriger ist8.
Obwohl Excel und Python ihre Vorteile haben, fehlt ihnen die für den Schutz des gesamten Codes und der Daten erforderliche Programmiersicherheit, die für die Art der skalierbaren Supply-Chain-Optimierung, die in diesen Vorlesungen diskutiert wird, erforderlich ist.
Anmerkungen
-
Kompilierzeit bezieht sich auf die Phase, in der der Code eines Programms in ein maschinenlesbares Format umgewandelt wird, bevor er ausgeführt wird. Laufzeit bezieht sich auf die Phase, in der das Programm tatsächlich vom Computer ausgeführt wird. ↩︎
-
Dies ist eine sehr grobe Annäherung an den Prozess. Die Realität ist viel komplexer, aber das ist Aufgabe der Computerfreaks. Im Moment geht es darum, dass die Array-Programmierung einen viel schlankeren (und kostengünstigeren) Berechnungsprozess ermöglicht, dessen Vorteile im Kontext der Supply Chain vielfältig sind. ↩︎
-
In einfachen Worten bezieht sich dies auf die Manipulation und Kombination von Zufallswerten, wie z.B. die Berechnung des Ergebnisses eines Würfelwurfs (oder mehrerer hunderttausend Würfelwürfe im Kontext eines großen Supply-Chain-Netzwerks). Es umfasst alles von einfacher Addition, Subtraktion und Multiplikation bis hin zu viel komplexeren Funktionen wie der Berechnung von Varianzen, Kovarianzen und Erwartungswerten. ↩︎
-
Stellen Sie sich vor, Sie versuchen, ein echtes Rezept zu perfektionieren. Es gibt möglicherweise ein Grundschema, auf das Sie zurückgreifen, aber es ist schwierig, das perfekte Gleichgewicht der Zutaten und Zubereitung zu erreichen. Es gibt nicht nur geschmackliche Überlegungen bei einem Rezept, sondern auch Texturen und Aussehen. Um die perfekte Version des Rezepts zu finden, macht man winzige Anpassungen und beobachtet die Ergebnisse. Anstatt mit jeder erdenklichen Zutat und Kochutensilie zu experimentieren, macht man aufgrund des beobachteten Feedbacks bei jeder Iteration gebildete Anpassungen (z.B. etwas mehr oder weniger Salz hinzufügen). Mit jeder Iteration lernt man mehr über die optimalen Proportionen und das Rezept entwickelt sich weiter. Im Kern ist dies das, was differenzierbare Programmierung und stochastischer Gradientenabstieg mit dem numerischen Rezept in einer Supply-Chain-Optimierung tun. Bitte lesen Sie die Vorlesung für die mathematischen Details. ↩︎
-
Wenn eine starke Affinität zwischen zwei Produkten im Katalog festgestellt wird, kann dies darauf hinweisen, dass sie komplementär sind, d.h. sie werden oft zusammen gekauft. Wenn Kunden zwischen zwei Produkten mit einem hohen Grad an Ähnlichkeit wechseln, kann dies auf einen Ersatz hindeuten. Wenn jedoch ein neues Produkt eine starke Affinität zu einem vorhandenen Produkt aufweist und zu einem Rückgang des Umsatzes des vorhandenen Produkts führt, kann dies auf Kannibalisierung hinweisen. ↩︎
-
Es versteht sich von selbst, dass dies vereinfachte Beschreibungen der mathematischen Operationen sind. Die mathematischen Operationen sind jedoch nicht besonders verwirrend, wie in der Vorlesung erklärt wird. ↩︎
-
Beliebte Versionsverwaltungssysteme sind Git und SVN. Sie ermöglichen es mehreren Personen, gleichzeitig an demselben Code (oder Inhalt) zu arbeiten und Änderungen zusammenzuführen (oder abzulehnen). ↩︎
-
Eine persistente Append-only-Schicht bezieht sich auf eine Datenablagestrategie, bei der neue Informationen in die Datenbank hinzugefügt werden, ohne vorhandene Daten zu ändern oder zu löschen. Das append-only-Sicherheitsdesign von Lokad wird in den umfangreichen Sicherheits-FAQs behandelt. ↩︎